
Making Iceberg Real-time


Apache Iceberg is the latest entry in the never ending quest for a simple, single way to store and process data at scale. Taking over from the enormously successful Apache Hive, it was created to:
Provide a single store of large amounts of raw data in a very cost effective way - in the modern cloud native world this means object storage.
Allow consumption of this data using a universal language (SQL)
Iceberg was initially built to solve Hive’s problems:
Slow query planning at scale (Hive required listing every partition)
Lack of ACID guarantees (concurrent writes could corrupt tables)
Schema evolution required full table rewrites
No time travel or snapshot isolation
And perhaps more importantly:
Provide an open, well-documented standard. in data serving that can be implemented in many engines (no vendor lock in).
Scale to handle the largest possible datasets (essentially infinite)
As Iceberg adoption began growing people quickly saw the opportunity afforded and began looking beyond simple batch workloads to more modern data ingestion approaches. As usual Postgres is ahead of the game, the team at Mooncake Labs built Moonlink: a real-time ingestion engine that moves data from Postgres directly into the open-table format Apache Iceberg. This was recently acquired by Databricks and similarly, Snowflake’s acquisition of CrunchyData produced pg_lake with a similar goal of unifying Postgres and downstream Iceberg.
Data streaming needs to catch up! Unfortunately, however, real-time Kafka workloads such as these are not a good fit for Iceberg where every new write must:
Generate data files (e.g. Parquet files)
Write manifest files describing those data files
Atomically update table metadata
Today an intermediate system is needed to ingest Kafka data and provide an analytical interface to it. Many powerful options exist (Clickhouse, Pinot, Druid, etc.) but they all lack the “single store” benefits offered by a lake approach. If you wish to query both real-time and batch data (from Iceberg) today, complex extra steps (e.g. Confluent Flink snapshot queries) are required to combine the two views of the world.
What does great look like?
The above is far from optimal but what would great look like? The answer to this is simple. The optimal solution would provide a seamless dataset that stretches all the way from the newest real-time data point (written 1 nanosecond ago) to the oldest point available (written 5 yrs ago). Users would be able to interact with this view using the tools and techniques they use today (SQL) without adopting any special procedure or additional technologies. In fact, the surest sign that this optimal solution has been achieved is that its users do not even know it exists.
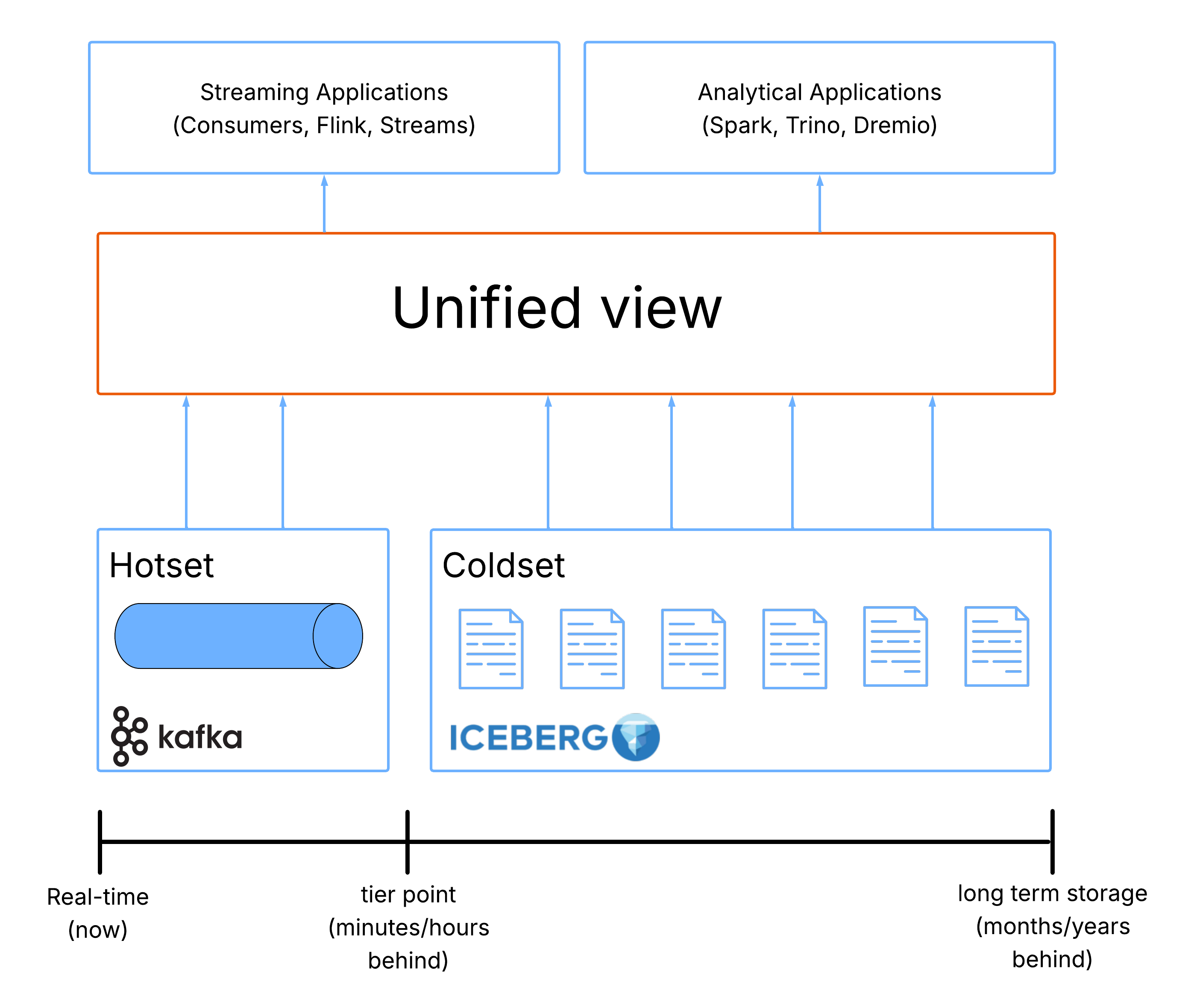
What if everything was Iceberg? What if everything was Kafka?
Achieving the above is actually remarkably simple, we just take the interfaces offered by each system and apply them globally. We need something akin to a proxy layer that serves Kafka data as if it was Iceberg and Iceberg as if it was Kafka. Users could then use the proxy layer to fetch unified data, or skip it and access the underlying system directly when their requirements are satisfied.
Because the proxy layer would need to understand both Kafka and Iceberg, it can also trivially automate the movement of real-time data to the lake. This is exactly what we created at Streambased!
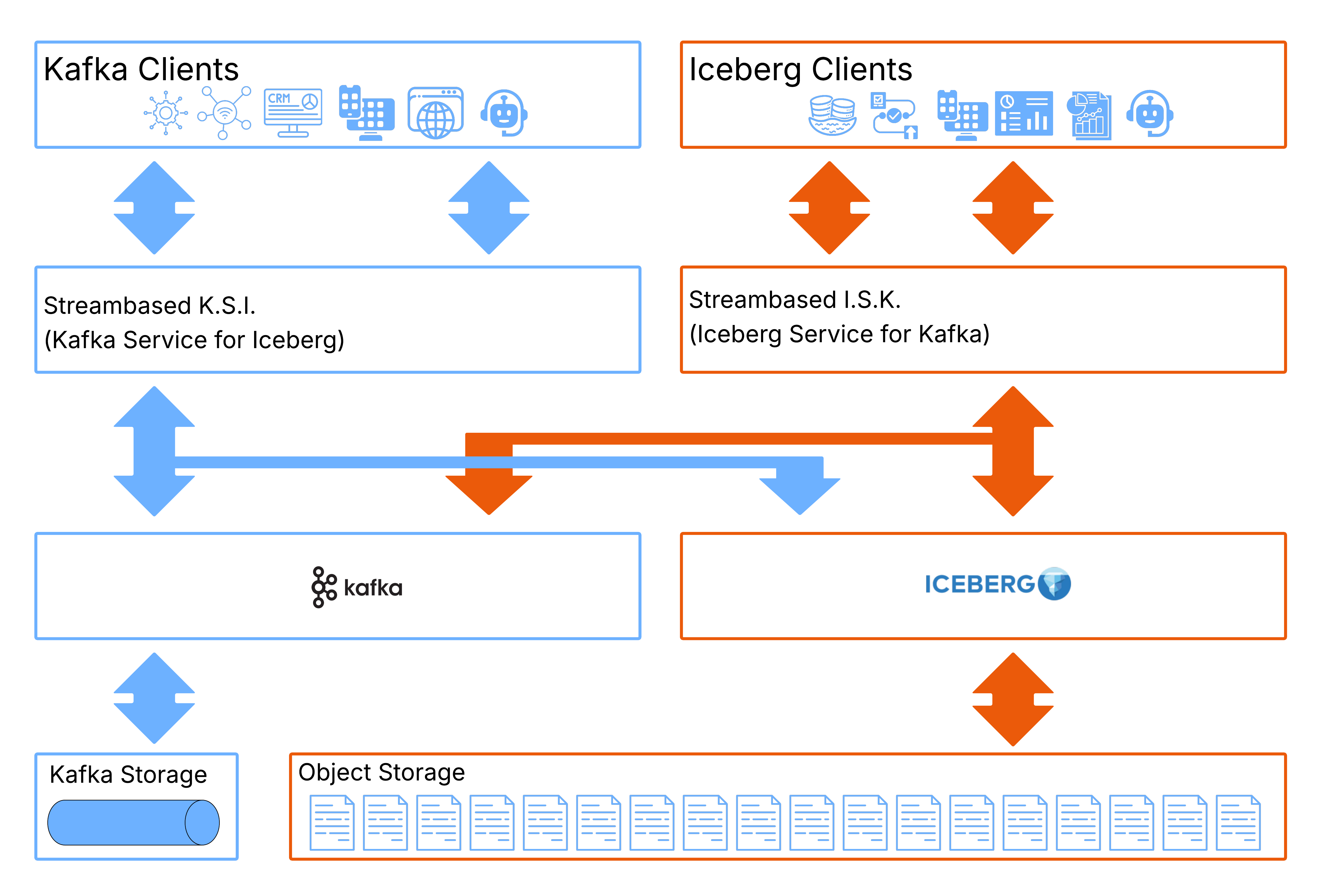
The How…
First some ground rules:
Building a seamless real-time/batch view must not compromise the performance of either system in isolation
The solution should not involve data movement (No ETL), the real-time and batch systems should always remain the source of truth for their data
To achieve this, we have two products - I.S.K. (Iceberg API on Kafka) and K.S.I. (Kafka API on Iceberg).
One Table Across All Time
Streambased I.S.K. presents a set of Iceberg tables in which the underlying storage can be composed of a section of real-time data from Kafka (the hotset) and a section of physical Iceberg data (the coldset). Tables in I.S.K. combine these two datasets in a way that is completely transparent to any clients interacting with it (it just looks like a regular Iceberg table).
For example, with I.S.K., ’SELECT * FROM transactions’ executed from Snowflake would retrieve records stored in both the transactions Iceberg table and the transactions Kafka topic and mix them together to provide a seamless table.
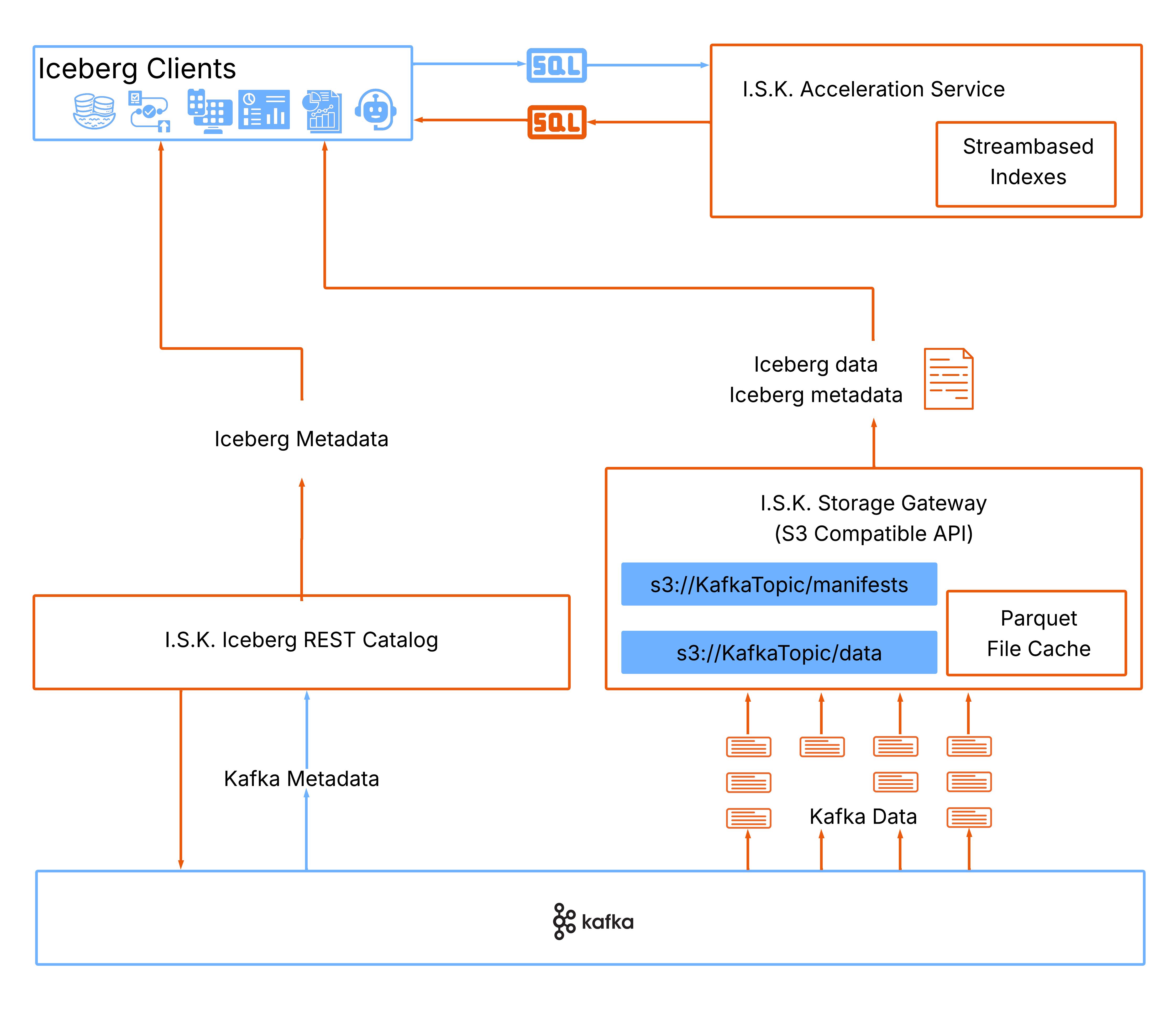
The I.S.K. architecture consists of the following components:
A storage gateway - Iceberg is expecting files so I.S.K. must have a way to provide a file based interface to engines. I.S.K. presents an Amazon S3 compatible API to engines that can serve both metadata and data files with data sourced from Kafka.
An Iceberg catalog - I.S.K. presents a simple, read only, catalog for Kafka data, this is the entrypoint for Iceberg engines.
A cache - To reduce impact on the Kafka cluster and improve Iceberg performance, I.S.K. caches files served by the storage gateway. These files represent sections of immutable Kafka log and so can be cached and invalidated at will.
An indexing engine - Most Iceberg queries will not address the entire dataset. The Kafka API does not allow access patterns that easily address subsets of data. To address this I.S.K. maintains indexes that map Iceberg partitions -> Kafka offsets, making Iceberg engines able to prune away the Kafka data they do not need.
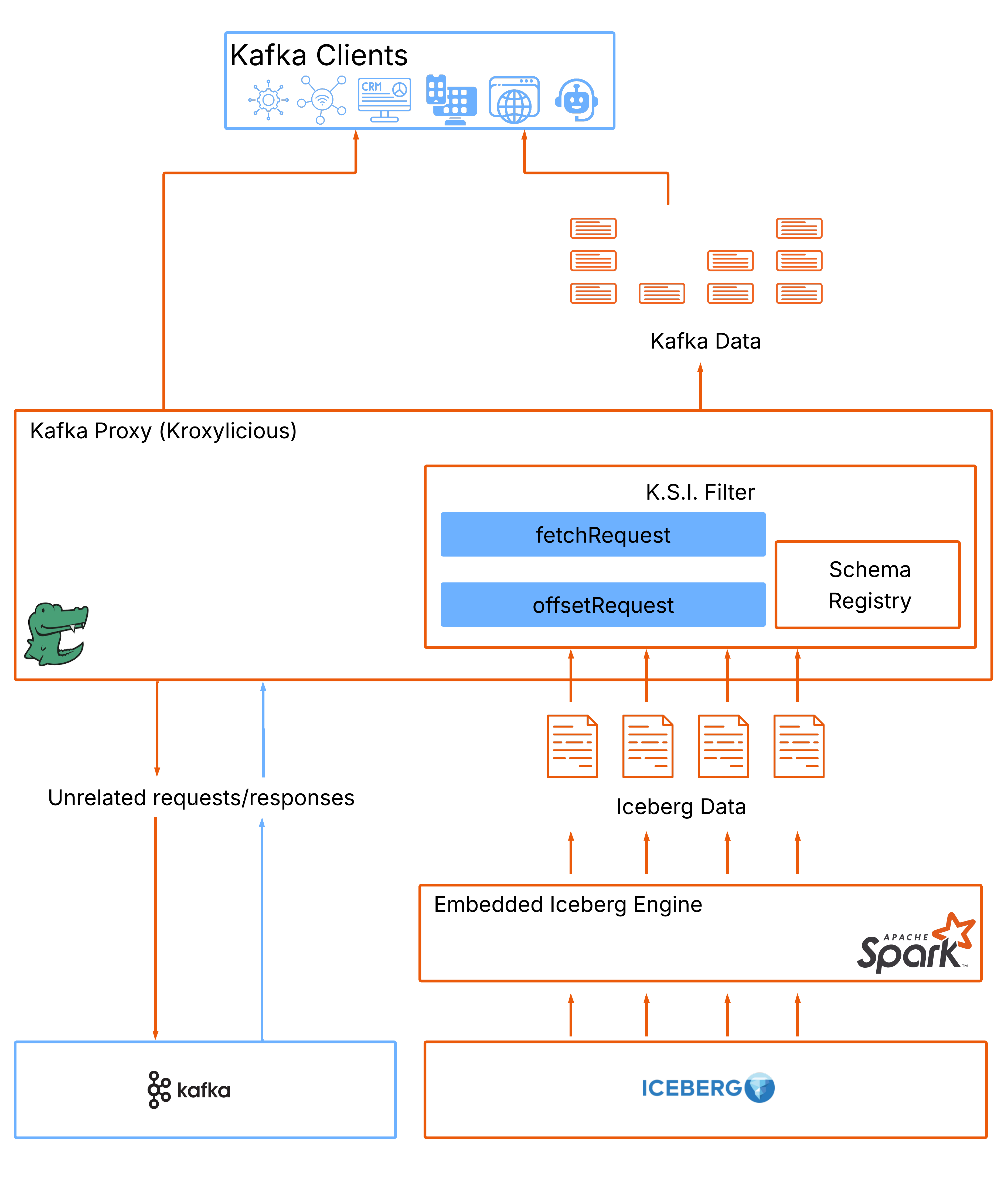
One Stream Across All Time
Streambased K.S.I. presents a number of Kafka topics in which the underlying storage can be composed of the same “hotset” section of data served directly from Kafka and “coldset” section served from Iceberg that I.S.K. uses above. K.S.I. maps columns from the Iceberg tables to Kafka’s partition and offset concepts allowing Kafka clients to interact with them as if they were Kafka topics.
For example, with I.S.K., a console consumer execution like:
kafka-avro-console-consumer --topic transactions --bootstrap-server ksi:9192 --from-beginning
Would start by reading older records from the transactions Iceberg table before progressing to newer records in the transactions Kafka topic.
The K.S.I. architecture is simpler than I.S.K. as the access patterns are a lot more limited. It consists of:
An Iceberg engine - to fetch table formatted data
A row processor - to converts Iceberg table rows into Kafka messages - This component reformats the column oriented Iceberg data into the key/value based messages Kafka clients expect. Governance steps like Schema Registry integration are applied here too.
A proxy (we use the open source Kroxylicious) - to serve Kafka clients. Most requests/responses will be passed through to the underlying Kafka cluster but fetch requests that reference cold stored Iceberg data will be served by K.S.I. and not the underlying cluster.
With I.S.K. and K.S.I., users can query and consume data continuously from the freshest event to the oldest record without ever worrying about synchronization or data duplication.
TL;DR: Streambased makes real-time and historical data behave like a single Iceberg table or a single Kafka topic, eliminating ETL, preserving performance, and unifying streaming + batch workloads on one logical layer.
Stop stitching systems together. Start using a real-time lakehouse that just works.
If you’d like to read about what we learned building this: