
The 9 Ways to Move Data Kafka -> Iceberg
An in-depth comparison of each vendor’s solutions exploring the trade-offs between zero-copy and copy architecture


If you were to intentionally design two protocols/formats with poor interopability, you would be hard pushed to create something worse than Kafka protocol and Apache Iceberg. Both standards were developed and optimised for entirely different purposes and share almost nothing in common:
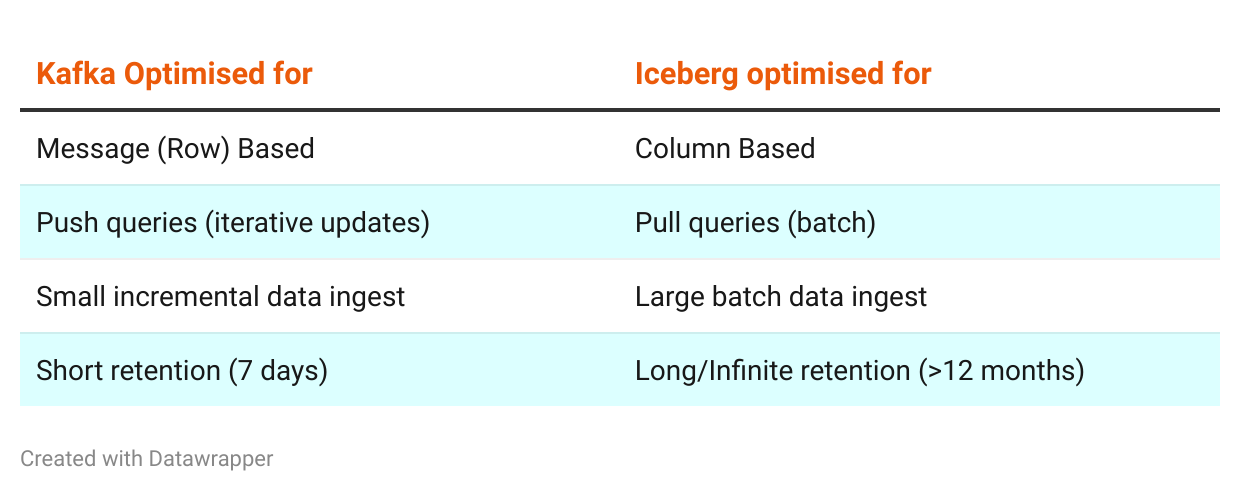
That said, the promise that the unification of these two projects brings is too tempting to pass up. If we were able to combine Iceberg and Kafka, we’d have a single continuous view of data from right this very millisecond all the way back to the beginning of time. No data inconsistency, no mental overhead in figuring out where to pull data from.
For this reason almost all vendors are currently building towards this goal. In flows of this type Kafka is the entry point, providing an easy place to land data for real-time serving to the more latency sensitive use cases. Things like microservices, web apps and observability platforms that need to give you answers in seconds, not hours.. Iceberg, on the other hand, provides long term storage for tasks that can wait for hours or days. Things like reporting, strategic decision making and AI/ML tasks.
Most importantly, any single data point has its place in both systems. I t may be processed in your microservice for your webapp, and then recorded for longer-term analysis by your CEO. This creates a natural flow of data from Kafka to Iceberg but this flow is not without its twists and turns. Let’s look at the 4 big issues:
Issue 1. Data Freshness 🕒
Kafka likes to pass messages around in small batches (~16KB). Conversely, Apache Iceberg works best when data is written in large chunks (~512MB). This mismatch is usually addressed by adding a step in the transfer flow that accumulates a number of small messages (usually driven by a total size in bytes or a time period) into a larger chunk before writing to Iceberg.
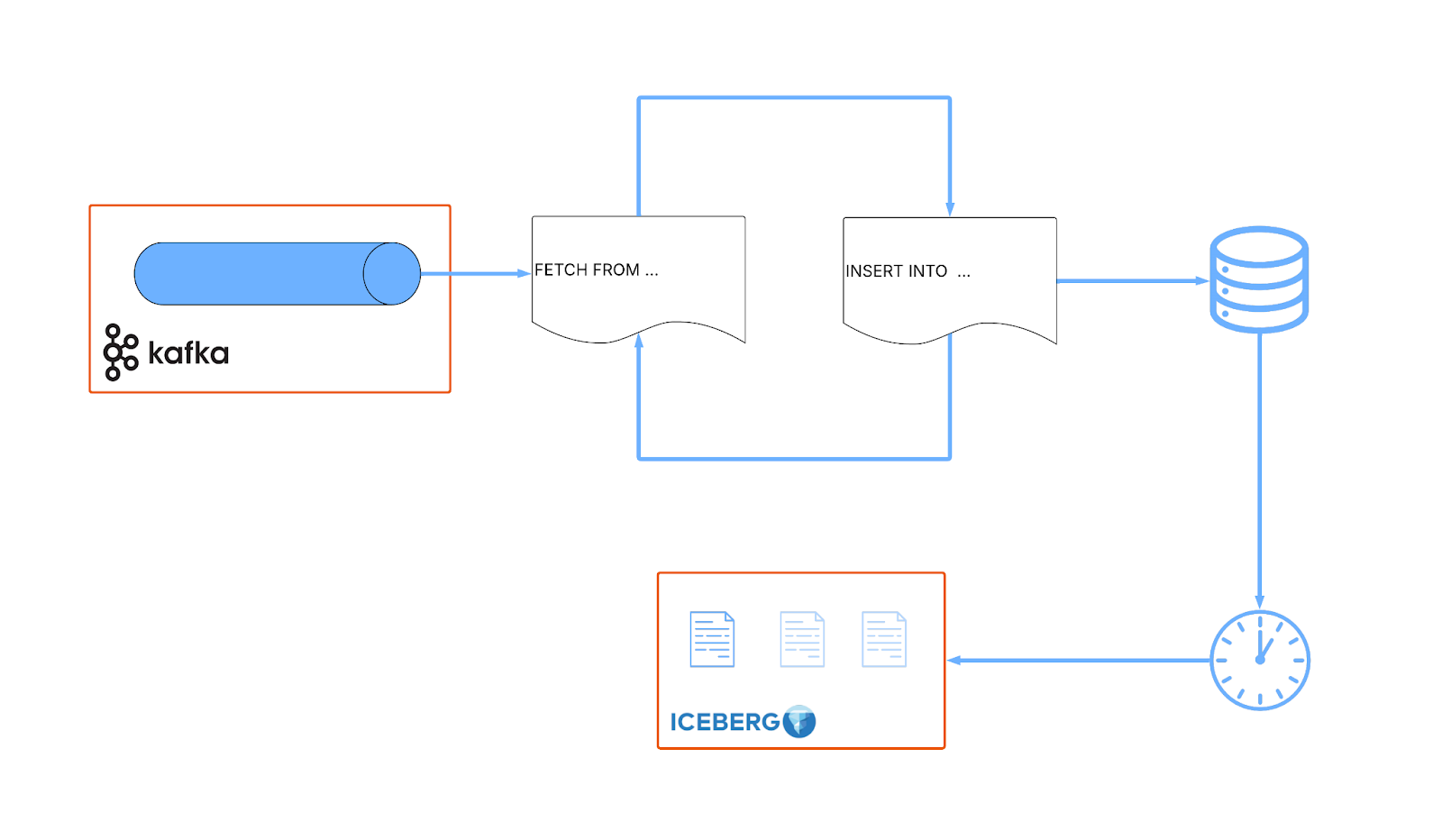
This inevitably results in time spent waiting. The downside of that is a reduced freshness of data available in Iceberg. The accumulation period means no Iceberg ingestion is happening until the batch size is hit. This creates a minimum lag time (> 15mins). In practice, this means you’re never able to use your beloved SQL in describing something that happened now
Issue 2. Table Maintenance 🧹
Apache Iceberg requires that a number of recurring maintenance procedures are executed on any dataset stored within it. The most common of these are:
1. Compaction - Iceberg is a file based format and, as mentioned above, Iceberg likes these files to be large. Even with a wait time for accumulation, hitting the right size in time isn’t always possible. It’s common for Iceberg deployments to end up holding files that are smaller in size than optimal. This hurts query performance. Compaction is Iceberg’s mechanism for fixing this - it combines the small files together into larger files.
2. Snapshot expiration - Snapshot’s in Iceberg represent the state of a table at a given time and are required for Iceberg’s time travel feature (time travel allows you to view a table at its previous state in history). Whenever new data is written to an Iceberg table a snapshot is created so that time travel can revert back to the table state before the write. Over time, these snapshots build up and make querying increasingly slower and more compute-intensive. Snapshot Expiration mechanism was created to delete older ones and restore performance.
Issue 3. Lacking a single source of truth 🧭
Any copy of data introduces the possibility of inconsistency. Corruption, duplication, schema skew are but a few examples of what can happen when the same data point is written across many destinations. There are many ways to slice the Kafka -> Iceberg flow to reduce or promote duplication between the two systems. Each offers different trade offs and hence must be evaluated carefully.
Issue 4. Partitioning 🗂️
Both Kafka and Iceberg have the concept of a partition but they are vastly different in meaning.
In Kafka: a partition is a separate log. It acts as unit of concurrency used only to parallelise processing.
In Iceberg: a partition is an organisational structure imposed on data to allow efficient querying. Iceberg partitions group similar data together and label it so that queries that reference that data know which groups are relevant to the query and which are not.
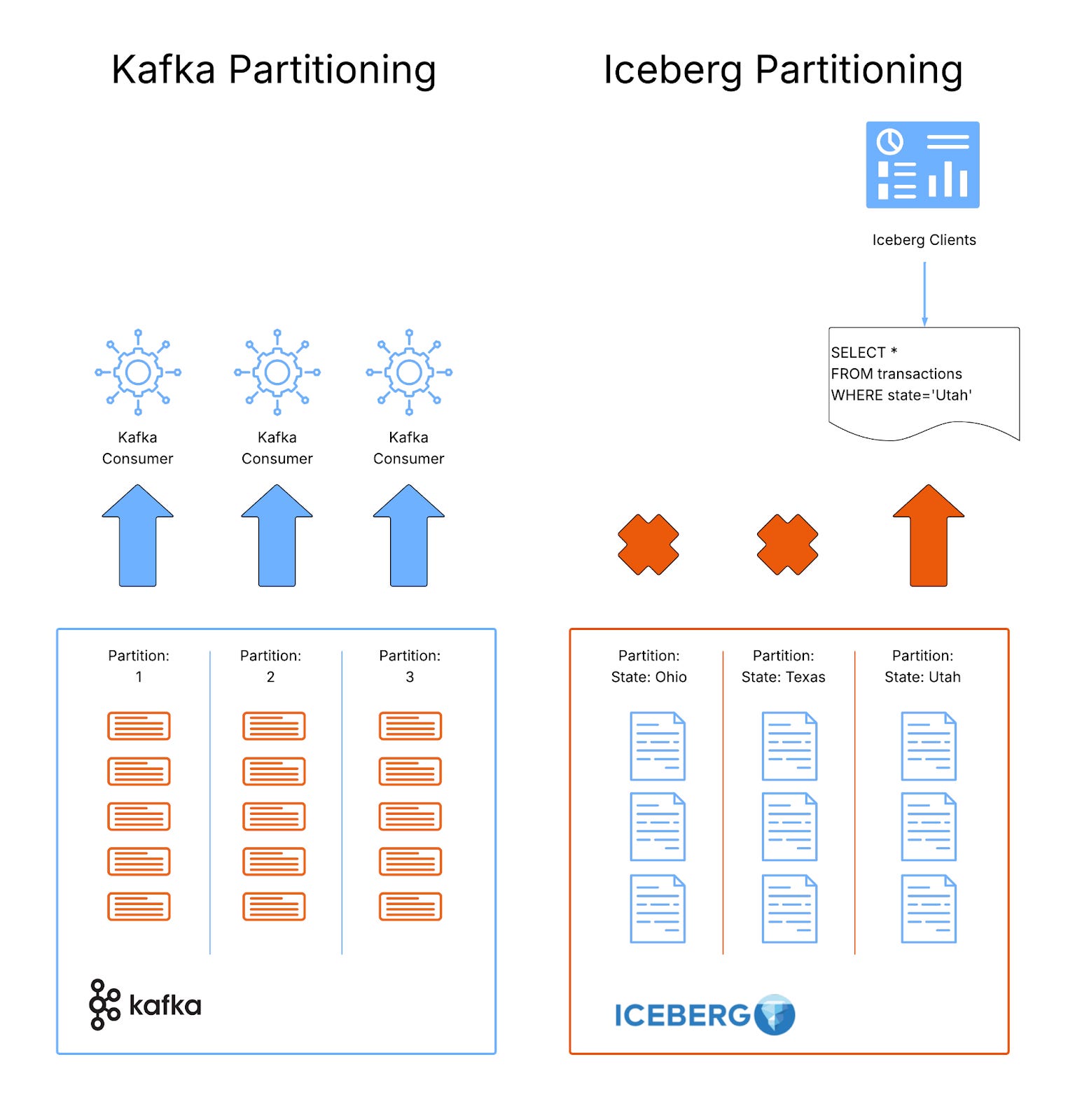
Effective partitioning in Iceberg means the difference between reading every file stored to satisfy a query and reading only a few relevant ones. It can increase query performance by orders of magnitude so must be considered.
Solutions
Ok, enough problems. Onto the solutions. There are 2 general approaches to the Kafka -> Iceberg flow today:
copy: those that simply copy data
zero copy: those that integrate the two systems more tightly.
First I will look at the former: systems that treat Kafka as the source for an analytically focused Iceberg copy.
🧾 Copy based solutions
In general these have the following pros and cons:
✅ Pros:
It is easy and generally not impactful to reorganise data in a copy - copies can have different partitioning, materialisation and other operations applied during the flow that make them better for analytical purposes without affecting the source Kafka.
Simplicity - Copies in Iceberg are separate from the original data in Kafka making it easy to understand the flow and resulting data sets.
⚠️ Cons:
Every copy of a dataset requires extra storage resources (and associated costs) and introduces the possibility for inconsistency.
Copies involve the transfer of data from one system to another and so , due to the laws of physics, mean that the destination system (Iceberg) must lag behind the source system (Kafka). With Iceberg in particular, reducing this lag increases table maintenance so a careful balance must be maintained to achieve optimal resource usage and availability.
Copy based solutions usually have a large maintenance overhead coming from external systems and practices that work alongside the main data transfer flow.
1. Kafka Connect
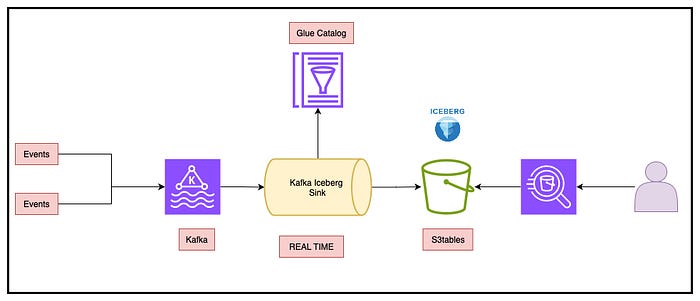
The Iceberg Kafka Connect Sink connector enables you to ingest records from Kafka topics and write them into Iceberg tables (on various storage backends) using the Iceberg table abstraction. As a core piece of the Apache Iceberg project it is open source, mature and feature rich supporting routing, schema evolution, table partitioning and external Iceberg catalogs (Hive, Glue, Nessie, etc.).
Its key advantage is integration with the Kafka Connect ecosystem. If you are already running Kafka Connect configuration is little more than a new library and some JSON. With that you get Connect’s scaling, fault tolerance, checkpointing, transforms (via SMT) and many other benefits. This is great if you have an existing Connect estate, however, if you do not have such an estate there is a steep learning curve in creating this platform before you can use the connector.
Unfortunately, like most connectors, the Iceberg connector considers its job merely to transport data. This means that table maintenance operations such as compaction and snapshot expiration must be handled separately. Also, due to the efficient data transfer focus there can be a significant lag between data creation in Kafka and availability in Iceberg (this is a common theme in copy solutions).
2. RedPanda Iceberg Topics

Iceberg Topics enables an additional flow in Redpanda to the regular log storage that persists topic data directly into Iceberg table format. Unlike the connect approach above this is handled within the broker without needing a separate connector/ETL process.
This closer integration means that RedPanda goes deeper into the downstream Iceberg tables providing features such as automated snapshot expiration and custom partitioning. RedPanda has also focused on the wider ecosystem, offering native integration with the largest Iceberg consumers (Snowflake/Databricks/AWS Glue) and their catalogs.
One current limitation of the RedPanda solution is the inability to backfill an Iceberg table from an existing Kafka topic. For instance, if your Kafka topic has a retention of 7 days and you enable Iceberg integration it will be a full week before the Iceberg table and Kafka topic are consistent. However, I spoke with the folks at RedPanda and they are actively developing a solution to this restriction and it’s due to be addressed in the near future.
RedPanda also provides other enterprise features needed to run an effective Kafka -> Iceberg solution such as a DLQ table for records that are incompatible with the destination Iceberg table and support for storage on all 3 major cloud providers.
The killer feature here is time to value, RedPanda have resolved many of the barriers to an effective Kafka -> Iceberg flow meaning you can be up and running in seconds, however, with enterprise features comes enterprise licensing and you will need one to use this feature .
3. Confluent TableFlow

Tableflow is a cloud based, managed Kafka -> Iceberg flow from Confluent Cloud similar to RedPanda’s above. If you are an existing Confluent Cloud user, you can materialize Kafka topics into open table formats such as Apache Iceberg or Delta Lake with a simple topic configuration.
TableFlow automates many of the common tasks needed when creating a Kafka -> Iceberg (or DeltaLake) pipeline including schema mapping / evolution, type conversions, compacting small files, publishing metadata to catalogs and many more. Like RedPanda, Confluent supports all major external catalogs (AWS Glue, Snowflake Polaris, Apache Polaris, Unity Catalog) but also provides the option to use its own catalog and storage for the true one-click up and running experience.
Confluent also provides other enterprise managed table features including compaction and snapshot expiration to keep tables clean and up to date. Furthermore, you can instruct TableFlow to do more than just make one to one copies of Kafka data, it supports Upsert/CDC modes to create materialisations based on keys/instructions.
The advantage of this solution is the maturity of the Confluent Cloud ecosystem. Confluent are able to leverage their mature cloud solution to create a “turn-key” experience that is trivial for existing Confluent Cloud customers. Unfortunately, this experience comes at a cost. TableFlow is significantly more expensive than its competitors today and locks you into the Confluent ecosystem.
4. WarpStream TableFlow
The newest entry into the Kafka -> Iceberg arena, Warpstream tableFlow is, like its namesake, a fully packaged solution for materialising Iceberg tables from Kafka data. Also like its Confluent counterpart, Iceberg tables created by Warpstream are fully managed right through data commitment, compaction, snapshot expiration and metadata management.
Where Warpstream’s solution differs is in it’s integration beyond the Confluent ecosystem. Warpstream TableFlow is a true BYOC system where you define source clusters (Kafka or Kafka-compatible from any provider) and designate where the resulting table data is stored (object storage buckets from any cloud provider either inside or outside Warpstream)
It supports integration with external catalogs and query engines. For example, you can register tables in catalogs (e.g. Glue, Snowflake, others) and provides guides on how to access this from the usual Iceberg engines (Trino, Spark, Clickhouse etc.).
Warpstream TableFlow also provides fine-grained data retention controls, allowing users to configure how long data is preserved at both the stream and table levels. Retention policies automatically manage snapshot expiration and file cleanup in object storage, ensuring that Iceberg tables remain compact, cost-efficient, and compliant with organizational data lifecycle requirements.
In summary, WarpStream’s TableFlow emphasizes simplicity, openness, and low-cost Iceberg materialization, while Confluent’s focuses on enterprise-grade governance, observability. There is significant overlap and it’s interesting to see such potentially competing products come under the same company umbrella.
5. AutoMQ Table Topics

Table Topics is a built-in AutoMQ feature that lets data sent to certain Kafka topics be automatically materialized into Apache Iceberg. Like RedPanda, you don’t need a separate connector or external streaming engine, and work with separate copies of the data for Iceberg and the Kafka log.
As above, AutoMQ handles the full Iceberg flow including file writing, metadata commits using internally managed services. All of these operations are coordinated inside the broker by services that piggy back on AutoMQ’s stateless, elastic and leaderless brokers. In AWS, AutoMQ is the only solution here that can integrate with the newer “S3 Tables” (a cloud provider managed data + catalog construct) so that the materialized tables use Amazon’s catalog and maintenance features (compaction, snapshot removal) and are queryable via Athena, etc. This is not yet available f
One early gotcha, however, is that it must be enabled at cluster deployment time and cannot be retroactively enabled like TableFlow and RedPanda. This means integration must be scheduled and managed in a much more intrusive way.
Like TableFlow AutoMQ’s implementation allows you to materialise tables using CDC/Upsert semantics and, in a similar way the data structures required for this are Schema Registry driven (usually Confluent Schema Registry or Aiven Karapace). Unlike TableFlow, AutoMQ is available outside of managed cloud services. The code behind its Table Topics (and all other features) is open source (Apache 2.0) and available to run on premise.
Ultimately, AutoMQ’s Table Topics is a powerful way to unify streaming and analytics, turning Kafka topics directly into queryable Iceberg tables without the need for separate pipelines or orchestration layers.
Summary of copy based solutions
We’re at the half way point 🏁 so let’s recap what we’ve seen so far:
Kafka Connect Iceberg Sink →open source and very flexible, if you can stomach its higher ops overhead.
Redpanda Iceberg Topics → Super easy setup for new topics/flows but cannot be imposed on existing data.
Confluent Tableflow → Enterprise-friendly but cloud only and vendor locked.
AutoMQ Table Topic → Best for tight cloud-native integration (eg. S3 tables) and open-source posture, but newer/less battle-tested.
⚡Zero Copy solutions
Up until now we have focused on solutions that maintain a clear separation between Kafka data and its Iceberg counterpart. These solutions generally force you to make an ugly choice between data freshness and Iceberg storage efficiency:
.png")
There is another class of solutions that address this trade off by integrating Kafka and Iceberg more closely. These typically share storage between Iceberg and Kafka in some way and eliminate copies. This provides reduced cost and improved consistency.
In general these have the following pros and cons:
✅ Pros:
Reduced lag - Zero copy solutions streamline the path of data from ingest to Iceberg by sharing storage between the two.
A Single Source of Truth - Any data written into a shared Kafka/Iceberg solution will be stored only once and accessed by both Kafka and Iceberg clients. This ensures total consistency between the two systems.
Cost reduction - Only one copy of the data is stored removing not only duplicated storage costs but management and reformatting costs too.
⚠️ Cons:
Restrictions - A tighter integration means that either side of the Kafka/Iceberg divide must take on aspects of the other. A good example of this is Iceberg partitioning. If a system is to read Iceberg data efficiently through the Kafka protocol it should be partitioned by Kafka partition and offset and not in a way more suited to analytical queries..
Complexity - Integrated solutions require much closer management of the underlying data and associated read/write paths. This adds complexity and hidden behaviour. Usually this is internal complexity, however and these solutions often appear simpler to the wider world.
6. Bufstream
Bufstream is a Kafka-compatible streaming platform that can stream data directly from Kafka topics into Iceberg tables (i.e. broker-side materialization). Bufstream was developed with cloud native object storage as the primary storage and with a focus on schemas right from the beginning, excellent building blocks for an Iceberg solution. In Bufstream’s, parquet files are written to object storage by the broker on produce and shared by both Iceberg and Kafka readers, avoiding duplicating data and creating a true zero copy layout. The trade off here is that object storage is on the write path and adds producer latency. Bufstream typically experiences 3-5x higher end to end latency (P99) than traditional Kafka.
Bufstream handles the associated Iceberg metadata and maintenance operations are taken care of inline with Kafka (retention etc.) and Iceberg (compaction, snapshot expiration etc.) requirements. Bufstream also supports the various external Iceberg catalog types (REST catalogs, AWS Glue, Google BigQuery Metastore) however there are constraints here because the data is shared. The most important of these is that Iceberg data is read only and does not support operations that rewrite the underlying data files. Shared solutions must serve Iceberg data back to Kafka so rewrites of that data by external engines can have unexpected consequences.
As schemas are a first class citizen in Bufstream, the integration is schema-aware, interacting with a schema registry (especially for Protobuf schemas) to derive Iceberg schemas, enforce schema compatibility, and do semantic validation.
In the end, Bufstream design brings streaming and lakehouse paradigms together under a unified schema model, providing consistent semantics across ingestion, storage, and consumption, with a latency cost…
7. Aiven Iceberg Topics

Aiven’s solution adds native Iceberg support into Apache Kafka itself via a custom implementation of Kafka’s pre-existing tiered storage mechanism. This splits Kafka data into two sections, a “hotset” stored in Kafka format to handle the most recent data and serve most Kafka clients and a “coldset” of older data that is transferred to object storage and persisted as Iceberg. This architecture is zerocopy because these two sets are interoperable, with the “coldset” able to be recalled to Kafka duty as required. This simply takes Kafka’s existing tiered storage flows (Kafka <--> S3) and changes the format (Kafka <--> Iceberg).
Unfortunately the reliance on tiered storage introduces some lag into the Iceberg path. Tiered storage was designed to facilitate the cheap storage of rarely utilised data and so typically allows a configurable but usually significant amount (>24hrs worth) of data to accumulate in the “hotset” before it is tiered. The time taken for this accumulation is also the time behind real-time that the Iceberg data will be.
By design, Iceberg Topics establishes a boundary around what is Kafka’s responsibility and what is Iceberg’s. Unfortunately this means that compaction, snapshot expiration and other Iceberg maintenance operations are beyond the scope of the plugin and will need to be added externally.
Tiered storage is one of the few pluggable areas of the Apache Kafka project and Aiven have added Iceberg features by extending their industry standard open source tiered storage plugin to include Iceberg support. If you’re already using Aiven tiered storage, adopting Iceberg is just a simple update and config switch.
Aiven’s Iceberg Topics plugin elegantly leverages Kafka’s tiered storage to unify streaming and analytical use cases without duplicating data, maintaining zero-copy interoperability between Kafka and Iceberg.
8. StreamNative Ursa

Ursa is a “lakehouse-native” streaming engine from StreamNative, which provides Kafka-API compatibility but writes data to open table formats (Iceberg, Delta Lake) on object storage. It uses a leaderless, stateless architecture taken from Apache Pulsar: rather than Kafka’s traditional brokers with leaders and replicas. This is an architecture similar to the recent diskless topics addition to the Kafka world but it has been in Pulsar from the beginning.
As a recently developed, Kafka compatible, engine Ursa is missing some features on the Kafka side, most notably topic compaction and transactions. Both of these are commonly used so could affect Ursa’s adoption rate.
Ursa includes stream storage + columnar storage layers: it writes a write-ahead log (WAL) for fast ingestion and then commits data into Parquet files (archive files) for analytic reads. It integrates with the usual bunch of external catalogs and some more specialised ones (e.g. S3 tables).
The use of a WAL introduces a similar lag problem to Aiven’s solution and, with similar boundary definitions, Ursa will not automatically handle compaction and snapshot expiration internally.
Also in a similar vein to Aiven’s solution, Ursa supports the use of the Iceberg layer to serve Kafka tasks (a true zerocopy). It even has a clever indexing system that spans both WAL and Parquet data to increase the efficiency of this.
Ursa combines streaming and lakehouse concepts through a Pulsar-inspired, stateless design that writes data directly into open table formats without traditional brokers. Its dual-layer storage model enables zero-copy interoperability while maintaining strong performance for both streaming and batch workloads.
9. Streambased
.png")
Streambased takes a completely original approach to this problem. Like tiered storage, it maintains the concepts of “hotset” stored in Kafka and a “coldset” stored in Iceberg. Where it differs however is that Streambased surfaces the hotset via protocol translation without requiring any data movement. The flow is such that, at query time, the latest hotset data is fetched from Kafka, transformed to Iceberg and combined with the coldset (already Iceberg) before being surfaced to the client. In this way clients see the entire dataset available to them from the latest data produced a millisecond ago to the oldest data stored in Iceberg since the beginning of time.
The big advantage of this approach is that there is, by definition, zero lag. Because the hotset data is fetched on demand at query time and not surfaced via an asynchronous background process, Streambased can guarantee that every Iceberg query is working with the very latest data available to it.
Such an approach means differences in resource usage too. Streambased decouples the pure Kafka load (produce) from the load incurred converting from Kafka to Iceberg. Other solutions mentioned here run background processes to do this conversion meaning that, when Kafka load spikes, so does conversion load. With Streambased the conversion load is coupled to the Iceberg query load not the Kafka write load, isolating the 2 usages.
Like Aiven, Bufstream and Ursa. Streambased can also serve Kafka data from Iceberg. Streambased K.S.I. (Kafka Service for Iceberg), is a Kafka proxy that federates incoming fetch requests between the hotset in Kafka and the coldset in Iceberg. Data from either is surfaced as appropriate to Kafka clients.
In deployment, Streambased is also a significant departure from the other solutions in this article. Streambased does not seek to replace or modify an existing Kafka instance, instead it sits as a layer above requiring only the public consumer and admin protocols to function. This means Streambased can be deployed rapidly on top of managed Kafka like Confluent or Bufstream and on prem open source distributions.
Streambased’s architecture redefines zero-copy by translating Kafka data into Iceberg format on demand, merging data at query time for truly real-time analytics. This eliminates latency entirely.
Solution Summary
As can be seen from this overview, all solutions in this space have the required building blocks to create an effective Kafka to Iceberg solution. The decision as to which technology to adopt will likely be driven by external factors rather than any particular feature. For this reason I’ve outlined which solution you may choose given some of these factors below:
For open-source, DIY control → Kafka Connect Sink is flexible but ops-heavy. Aiven and AutoMQ provide open source versions for customization.
For vendor simplicity → Redpanda Iceberg Topics and Confluent TableFlow offer simple enterprise style integration if you can accept the vendor lock-in.
For maximum data freshness → Streambased’s query-time translation guarantees zero lag between Kafka and Iceberg, ideal for real-time analytics and observability workloads.
For maximum compatibility → Streambased requires only the Kafka wire protocol so can function with any number of existing Kafka deployments.
For schema-first organisations → Bufstream’s schema-aware design ensures consistency and easier evolution across streaming and lakehouse layers.
For cost-efficient scalability → Ursa, Bufstream and AutoMQ’s stateless brokers and shared object storage reduce infrastructure costs while maintaining Kafka-compatible performance at scale.
Conclusion
The convergence of Kafka and Apache Iceberg represents one of the most exciting frontiers in modern data infrastructure. While each technology was born to solve fundamentally different problems, the demand for real-time decision-making has forced these worlds together. The appetite for a unified data view is strong as evidenced by the widespread support that has come so quickly after Iceberg won the table format wars.
The industry’s range of approaches, from traditional copy-based pipelines to innovative zero-copy architectures, underscores that there is no single “right” solution, only a spectrum of tradeoffs between cost, complexity, freshness, and control. Copy-based systems like Kafka Connect and TableFlow deliver predictable, well-understood architectures but introduce lag and duplication, while zero-copy systems like Streambased, Bufstream, and Ursa push the limits of what’s possible with shared storage and dynamic federation.
In this evolving landscape, the unification of streaming and analytical data systems is no longer a distant vision, it’s quickly becoming the default expectation for modern data infrastructure.
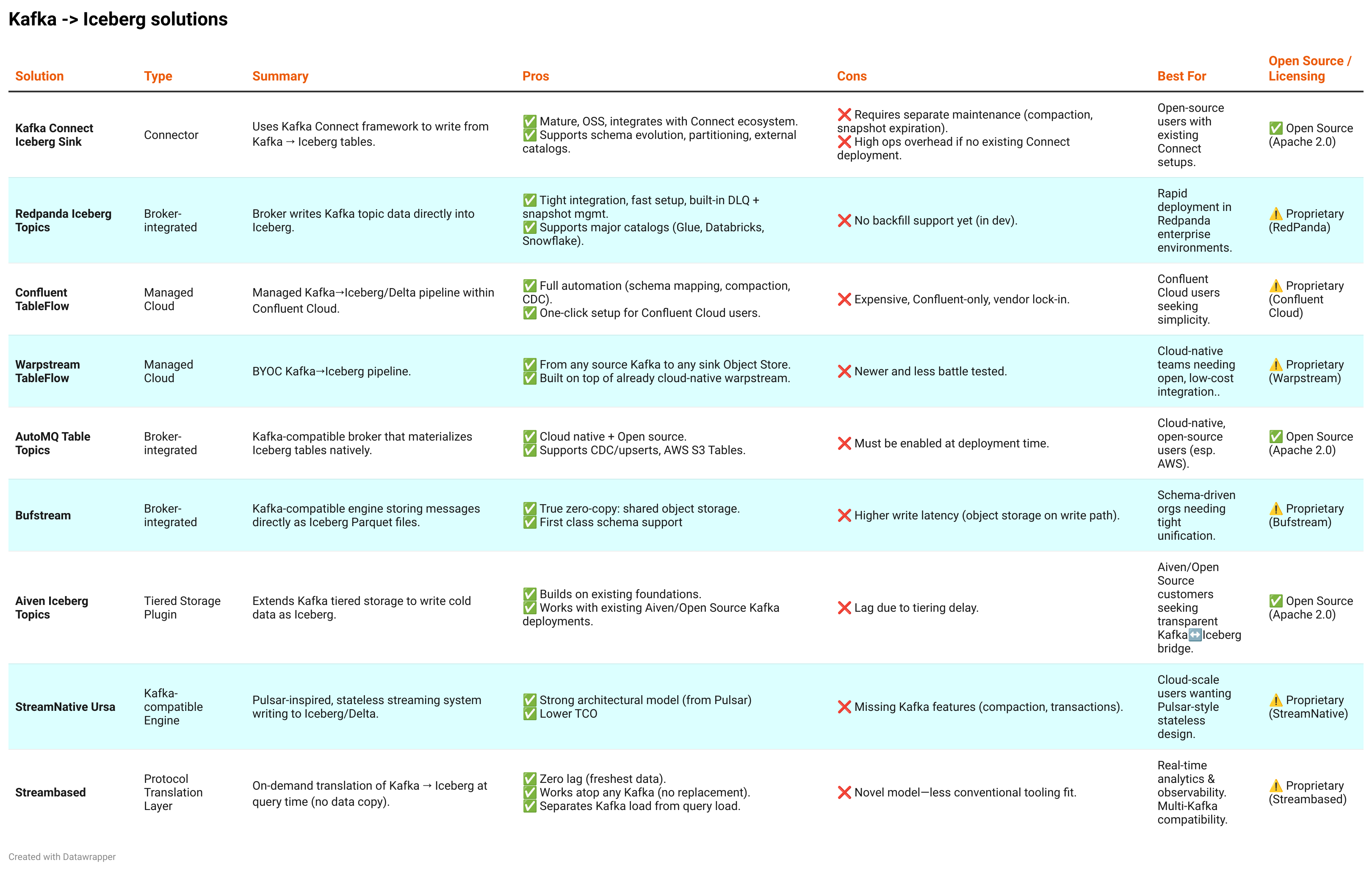
Please find a summary table below of all solutions side by side:
Nice analysis.
There is just one addition from StreamNative.
There is an option to use Lakehouse Tiered Storage [1] - that will work with Pulsar API and Kafka API so it can include Transactions and Compaction with Kafka.
BTW compaction is possible with URSA clusters. [2]
[1] - https://streamnative.io/blog/ursa-everywhere-lakehouse-native-future-data-streaming#ursa-storage-extension-for-classic-pulsar-lakehouse-for-all-deployments
[2] - https://docs.streamnative.io/cloud/build/kafka-clients/compatibility/kafka-protocol-and-features#supported-topic-configs
no apache flink and apache spark that have direct support from apache iceberg ?