
Why Kafka + Iceberg Will Define the Next Decade of Data Infrastructure
How two open standards can replace pipeline sprawl with a unified, low-cost, and future-proof data architecture.

Today’s data architectures are complex, but does it have to be this way? In this post I’m going to show how we can replace pipeline sprawl with 2 open standards to reduce cost, complexity and fragility to near zero.
Architectures grow organically, technologies and processes are chosen to suit a specific first case and, if successful, expand. The problem is that this is happening (and has been happening for the last 20yrs) concurrently across orgs across the entire business. The result: many disparate technologies connected by brittle pipelines.
For example, a simple retail company may have:
Started with a MySQL database for its point-of-sale system
Later added a SaaS CRM to track customer interactions
Then adopted a cloud data warehouse to support online analytics.
Then marketing spun up its own data pipeline into a separate BI tool
SREs added metrics to one system and logs to another
The CTO insisted on adopting the next big thing
The data science team set up their own Jupyter cluster with custom ETL jobs pulling from production databases
Shadow IT introduced spreadsheets and Google Sheets integrations as "glue" for missing workflows
[these are all things that I have experienced, add your own in the comments ;-) ]
Meanwhile:
Operations engineers maintain bash scripts that shuttle CSVs between systems
The warehouse has nightly jobs failing silently
Marketing dashboards rely on stale data
Customer service can’t reconcile records between CRM and order history
Data schemas become rigid and stale because of the impact of changes on downstream systems.
…
This story has been played out time and time again and always has the same conclusion. Data infrastructure eventually buckles under the weight of scale, regulation, and business complexity.
Standardization is one of the key levers for regaining control when architectures have grown in an organic, fragmented way. Consolidating around standards breaks down silos, reduces complexity and increases scalability.
This is not a novel idea, most cutting edge operational teams have already standardized around Kafka and similar leading analytical teams have already standardized around Iceberg.
Clear but isolated standards only solve half the problem however, leaving the fundamental disconnect between operational and analytical systems intact.
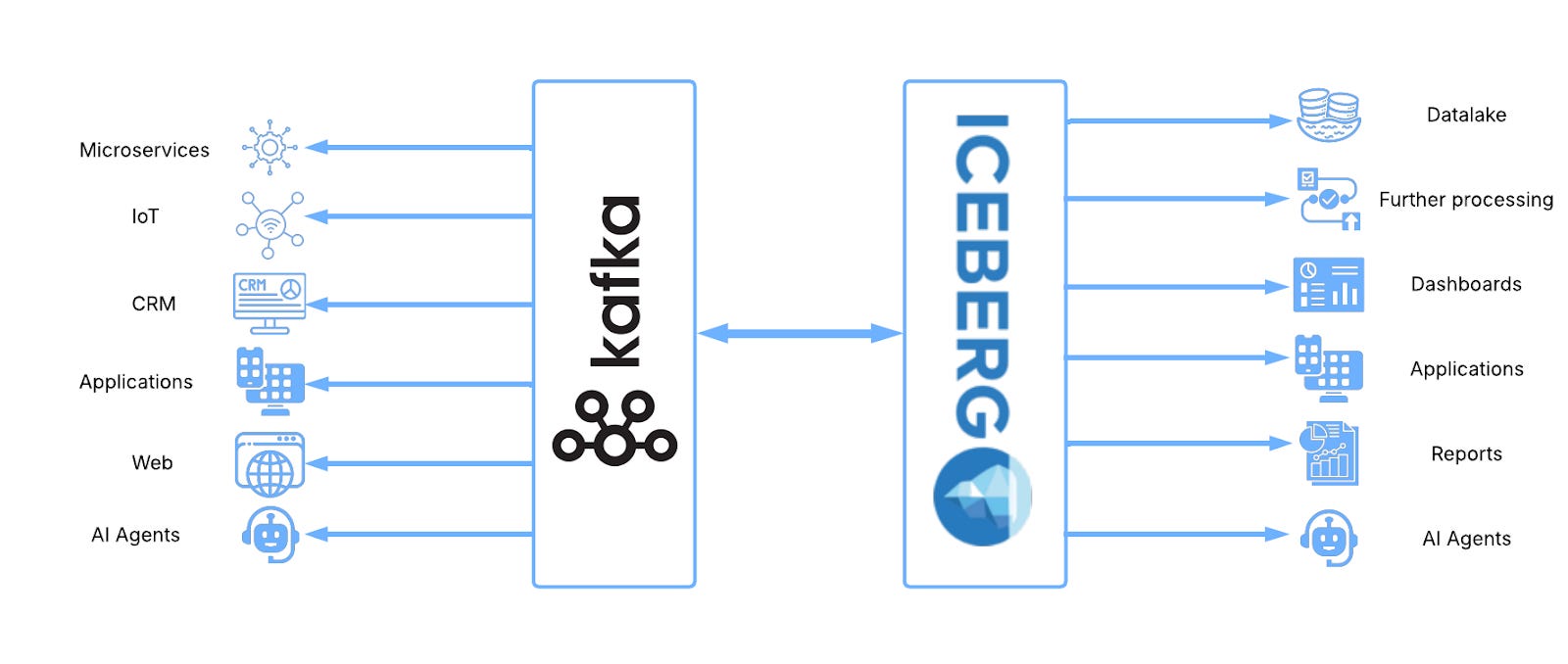
The combination of Kafka and Iceberg, on the other hand, is incredibly powerful because it finally resolves the decades-long tension between real-time operations and durable analytics. Used separately they still leave us with duplicated datasets, costly ETL jobs, schema mismatches, and latency compromises. Together, they create a unified architecture where streaming and batch pull together rather than against each other. An architecture much more powerful than the sum of its parts.
Let’s explore an architecture based exclusively on Kafka and Iceberg with the aim of achieving the gold standard in both operational and analytical arenas. Including:
Cheap long term retention - Store data for as long as it’s required without having to worry about mounting storage costs and maintenance overheads
A single source of truth - Achieve total consistency across the entire data estate
<100ms access - Clients on both sides of the operational/analytical divide should work with the latest data available
Easy evolution - Data should be able to evolve with the business, adopting volume change, schema evolutions and changing business needs at will.
The new (old) architecture
There is an architecture that fulfils these requirements and it’s actually a well understood, production proven one: The lambda architecture.
For many (including me) the Lambda architecture (proposed by Nathan Marz in 2011) was a first introduction to real-time data, stream processing and concepts beyond the high volume, batch based infrastructures that we all grew up on.
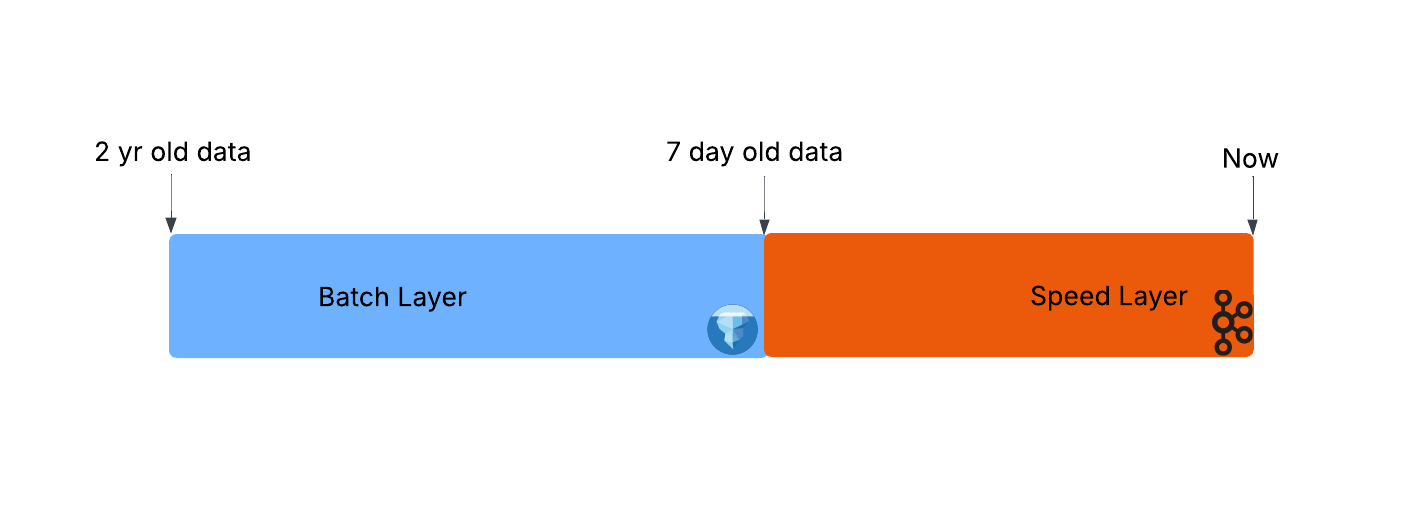
As a quick recap it consists of a batch layer that provides a long term (months/years), high lag (hours/days) view that is topped up with a speed layer that provides short term (<7 days) low lag (sub-second) data. A complete picture of the data can be built up by combining data from one or more of these layers.
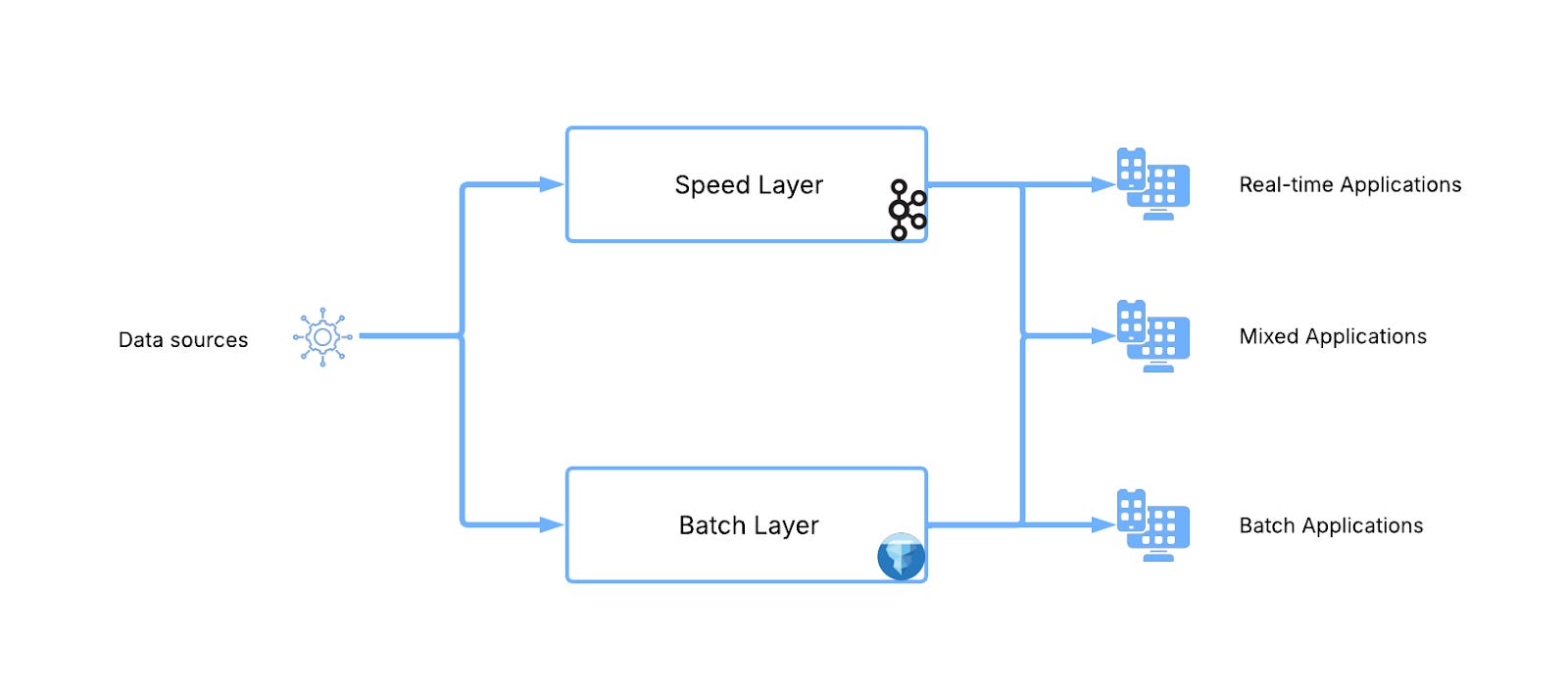
The issue with this architecture is that Speed and Batch layers typically have vastly different access patterns and concepts. This makes Mixed Applications (where the most power lies) complex to develop, manage and evolve. For example, Speed Layer applications must routinely address situations like late arriving, out of order data etc., concepts that simply aren’t present in the Batch layer.
The fundamental problem here is that batch and speed speak very different languages, but what if they didn’t? What if they both spoke Iceberg?
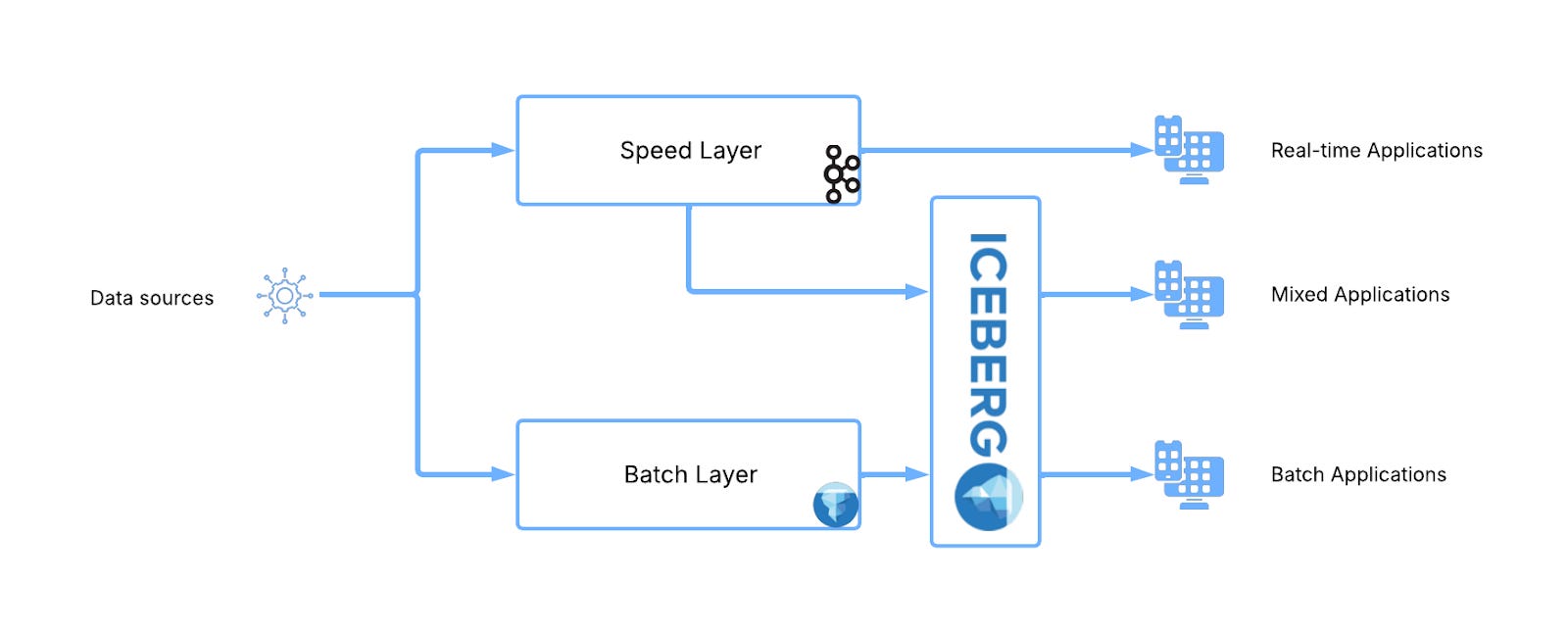
Suddenly both our batch and speed layers speak Iceberg and unifying both data flows becomes a trivial problem
In our new architecture both speed layer and batch layers are represented as Iceberg tables and the combination of them both can be achieved with a simple union:
SELECT *
FROM
speed_layer
UNION ALL
batch_layerTraditionally this union was done by a complex client system (Apache Beam anyone?) but recently speed critical OLAP databases like Apache Pinot are filling this role. However having everything in Iceberg means no client system commitment must be made and any processing engine supporting Iceberg (Spark/Dremio/Trino etc etc..) can be used.
So how do we implement this?
#NoETL
The traditional way to solve this problem was to have an ETL process (Kafka Connect is a great one) that sits between Kafka and Iceberg to copy the data across into a second, analytical dataset. Unfortunately this approach involves compromising on the Single Source of Truth and <100ms goals:
Copies of the data - Any ETL process copies data from the operational layer (Kafka) to the analytical layer (Iceberg). Since these layers evolve independently, inconsistencies can arise. For example, if Kafka records are accidentally duplicated in Iceberg, can Iceberg still be trusted? Or if Iceberg enforces business rules (e.g., amount ≥ 0) that Kafka doesn’t, can Kafka still be trusted?
High latency - Copy-based approaches also add delay. To store data efficiently in Iceberg, records must be batched into larger chunks. This batching often takes minutes to hours (typically ~15 minutes), during which the data is unavailable in Iceberg. For more detail see my LinkedIn post on this here
Not only that, but it forces you to contend with some troubling side effects:
High maintenance - ETL generally writes small and inefficient packets of data to Iceberg continuously and incur the maintenance overhead that comes along with this is large. (I’ve written previously on this here). Not only that but the operational and analytical realms often have different concepts making governance processes like schema evolution challenging.
High storage costs - ETL requires keeping two full copies of the data: one in Kafka for operations, and another in Iceberg for analytics. This duplication inflates storage bills dramatically when volumes are high.
It has to be a view
Surfacing the Speed Layer as Iceberg is not as simple as it seems. This process must retain the ultra low latency access expected from the speed layer but Iceberg is not optimised for this at all.
ETL processes can not achieve this, instead we can rely on a trusted mainstay of database systems: Logical views.
Logical views involve result sets computed at query time rather than pre-computed and so are guaranteed to work on the latest available data and achieve the latency goals we are looking for. What’s more, they needn’t be any more complex than their ETL counterparts, it’s the same processing taking place just executed at a different point.
This creates an Iceberg-like layer over Kafka that can be accessed by processors in the same way as any other Iceberg store. When an Iceberg query is executed, the view calculates the data from Kafka required to satisfy the query, fetches it, transforms it to an Iceberg format and returns it. This all happens on demand, with the latest available data from Kafka. For more information see my recent LinkedIn post on this here
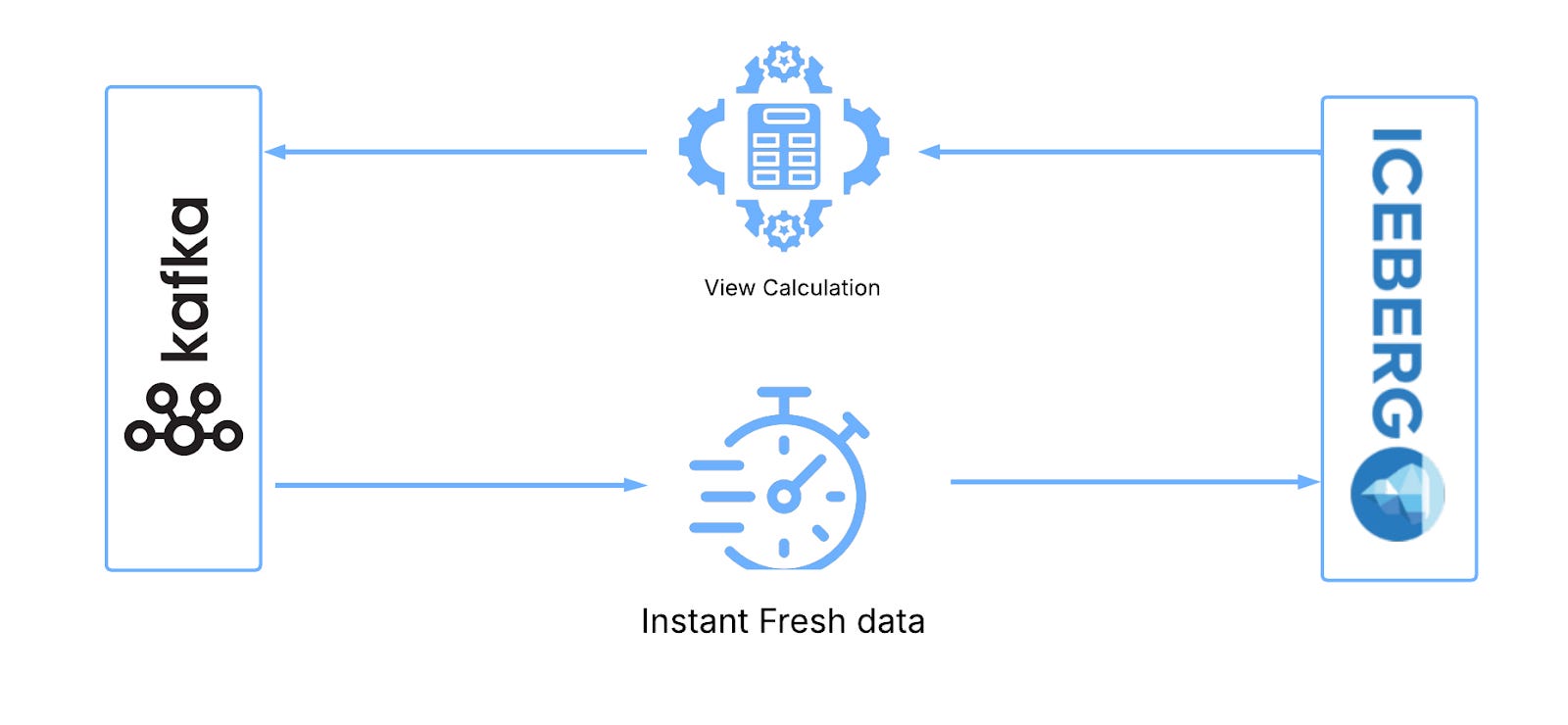
This comes with a number of advantages over ETL:
Always up to date - In a logical view data is fetched at query time, giving access to the complete latest-millsecond available data. Connectors/materialized views involve copies of the data that may lag behind the source.
Evolves with the source data - a logical view is guaranteed to be consistent with the source data meaning that any changes in the source data (schema evolutions, repartitioning etc.) are immediately reflected in the view. Other approaches require an expensive and time consuming replay of older data before evolutions are reflected. I’ve written on this previously here
Zero Copy - only a single copy of the data need be stored in Kafka, no separate Iceberg copies.
Putting it all together
The final step towards our complete architecture is to create a path to transition data from speed layer to batch layer. As both layers are represented by Iceberg tables in this architecture this can be as simple as an insert statement:
INSERT INTO
batch_layer
SELECT *
FROM
speed_layerCare must be taken to balance the sizes of Batch and Speed layers to maintain efficiency. However, as the transition process is just another Iceberg operation, it can be invoked at any point and there is no down time incurred. The transition process is as follows:
Initially the majority of data exists in the batch layer with only a small “head” held in the speed layer:


New data is written to the speed layer only, increasing the share of data it is responsible for serving:

When a threshold is reached (usually driven by Kafka topic retention) a move process is triggered to move data from speed layer to batch:
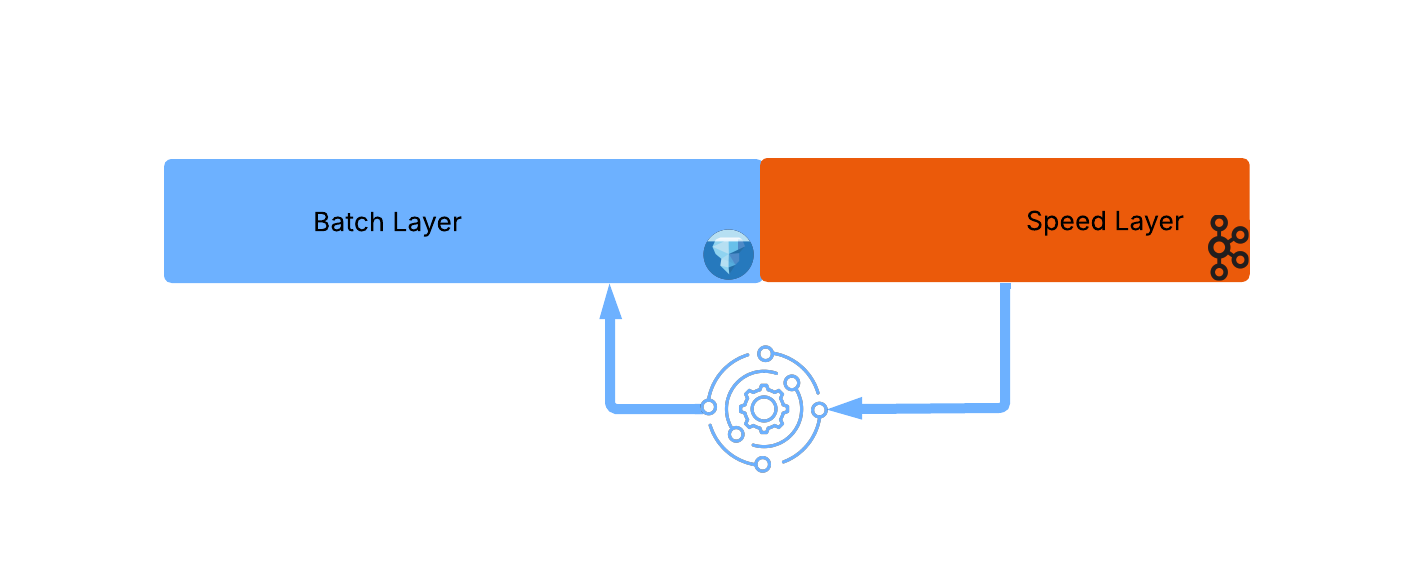
Note that this transition process involves moving a large amount of speed_layer data efficiently in large optimized chunks, thus avoiding the small files (compaction) and snapshot expiration issues usually associated with streaming to Iceberg
With this process complete we return to the initial state with the batch layer serving the majority of data and repeat the process again and again:

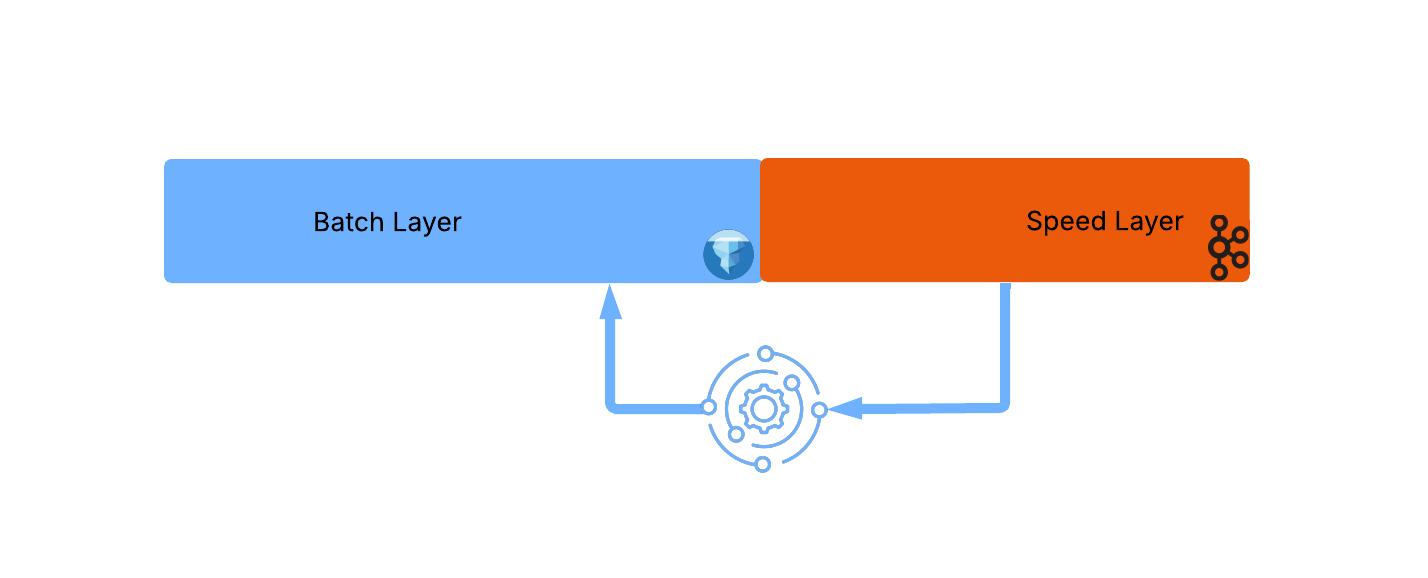

Conclusion
By unifying Kafka and Iceberg through a logical, view based, architecture we can finally dissolve the long-standing divide between operational and analytical systems. Instead of maintaining parallel infrastructures, duplicating data, and fighting constant trade-offs in latency and consistency, organizations can achieve a single, coherent data layer that is both real-time and durable.
This model not only simplifies architectures and reduces cost, but also empowers teams to build richer, mixed applications on top of a unified source of truth. In many ways, it delivers on the original promise of the Lambda architecture: speed and batch working together but with the elegance and efficiency of a single language: Iceberg.
We’ve spent the past 2yrs building this architecture at Streambased. Want to try it out? Drop me a DM: