
Kafka -> Iceberg Hurts: The Hidden Cost of Table Format Victory
Iceberg won the table format wars! And with victory come the spoils

Iceberg won the table format wars! And with victory come the spoils. The question on everyone’s lips now is: “How do we get our Kafka data into Iceberg?”.
Answers have ranged from a super simple Kafka connector to multi-stage, Flink-based pipelines but that’s not what this post is about.
Instead, we’re going to address the elephant in the room and ask the real burning question: “What happens when your Kafka data gets there?”.
If you’re a mature Iceberg user, chances are you are butting up against some fundamental Iceberg challenges that are only exacerbated by streaming data sources.
In this post we’re going to look at 3 of the most common and explore a novel approach to address them.
Snapshot Expiration
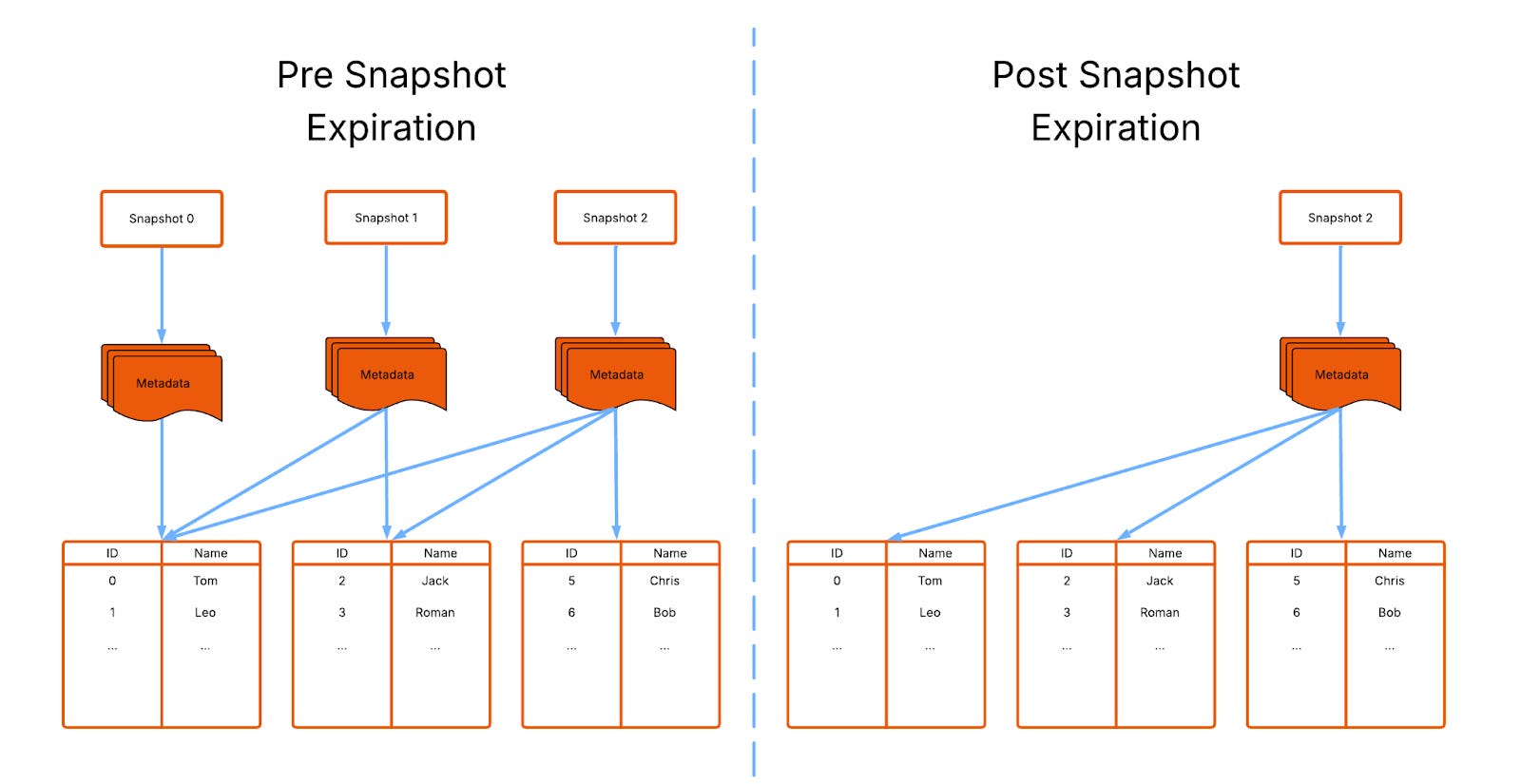
Time travel is a flagship feature of Apache Iceberg that allows queries to be executed against a table state at any point in the table’s history. It’s powered snapshots, a “snapshot”: a unique piece of metadata that points to all the data in the table at that time.
Imagine a situation where I insert 2 rows and then 30 seconds later insert a further 2. This action created 2 snapshots, the first pointing to a table with 2 rows and the second pointing to a table with 4.
Each snapshot is given a unique id, allowing you to time travel back to the table state at the snapshot:
SELECT * FROM someTable FOR VERSION AS OF 2188465307835585443 -> 2 rows
SELECT * FROM someTable FOR VERSION AS OF 4583289324735846932 -> 4 rowsImagine, for instance, that you wrote every message from an event stream individually to an Iceberg table via an “INSERT INTO” statement (a really bad idea). By default the number of snapshots would be equal to the number of messages (potentially millions per second)!
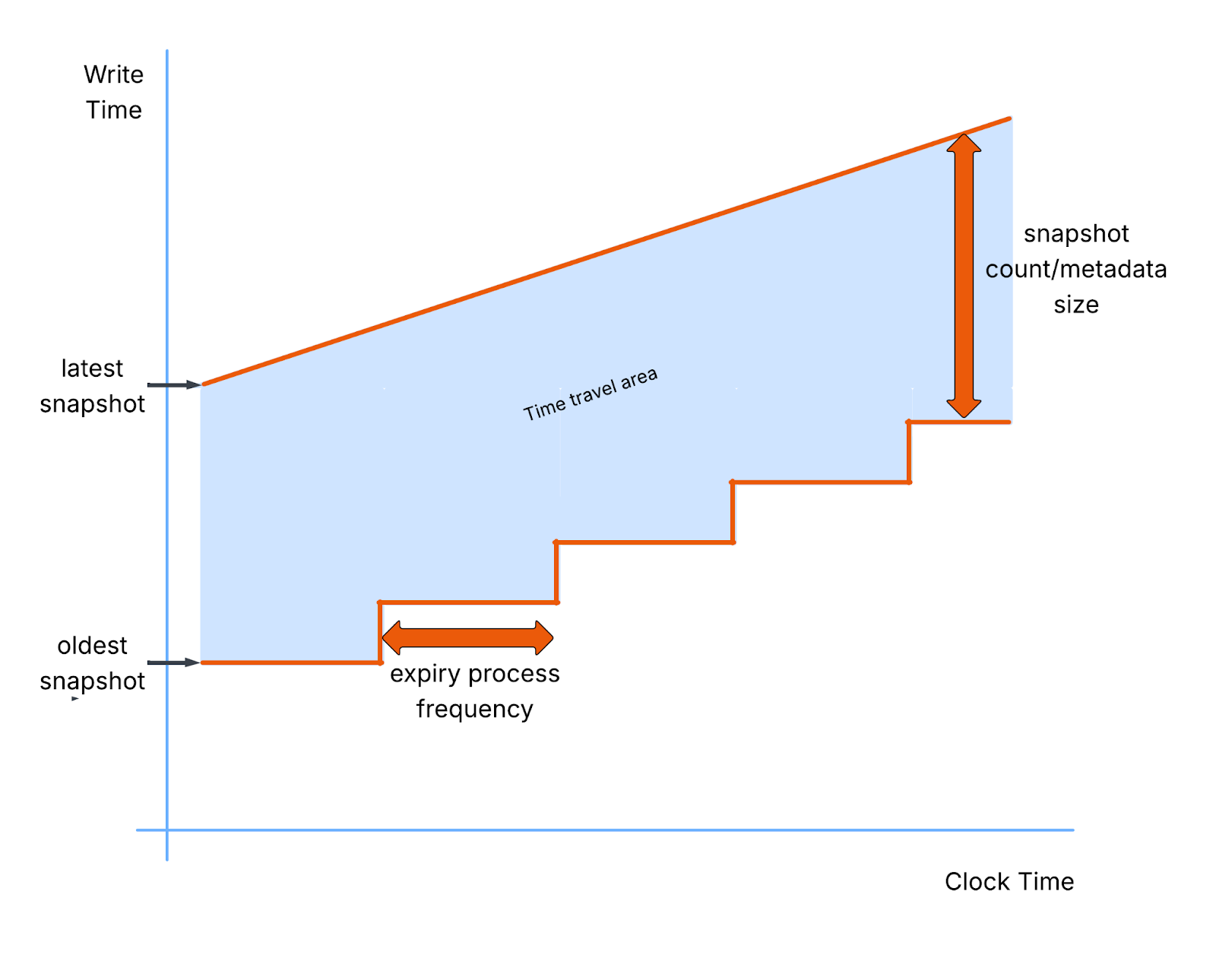
Thankfully snapshots are metadata only, so the cost of creating one is not huge, however frequent writes etc. create a lot of snapshot and hence a lot of metadata that must be managed. If snapshots are allowed to grow uncontrolled you can suffer from some serious side effects:
Delayed query planning - Processing metadata is the first stage in any Iceberg query, the more metadata, the longer this process takes.
Slower rollbacks - Iceberg rollbacks must traverse the snapshot list to find the correct snapshot to roll back to. The larger this list the slower this operation. Performance can be further hit if orphaned snapshot metadata is pruned during the rollback.
Degraded maintenance operations (e.g. compaction)
Increased resource consumption
The solution to this problem is Snapshot Expiration, a manually triggered Iceberg process where older snapshots are removed.
Remember however, that Iceberg is only a format so cannot do the expiration work by itself.
Instead it must rely on an external engine like Spark or Trino (or any number of other vendors) to perform it. Furthermore this is not an automated background process you can switch on and forget about, it’s a repeated batch job that must be scheduled and managed separately from read/write jobs.
Expiring a Snapshot can create its own problems! Once expired, Iceberg loses the ability to time travel to that snapshot so any queries run at that snapshot will fail.
In other words, your Iceberg administrator has to carefully balance metadata size against time travel capability manually in a never ending compromise.
Compaction
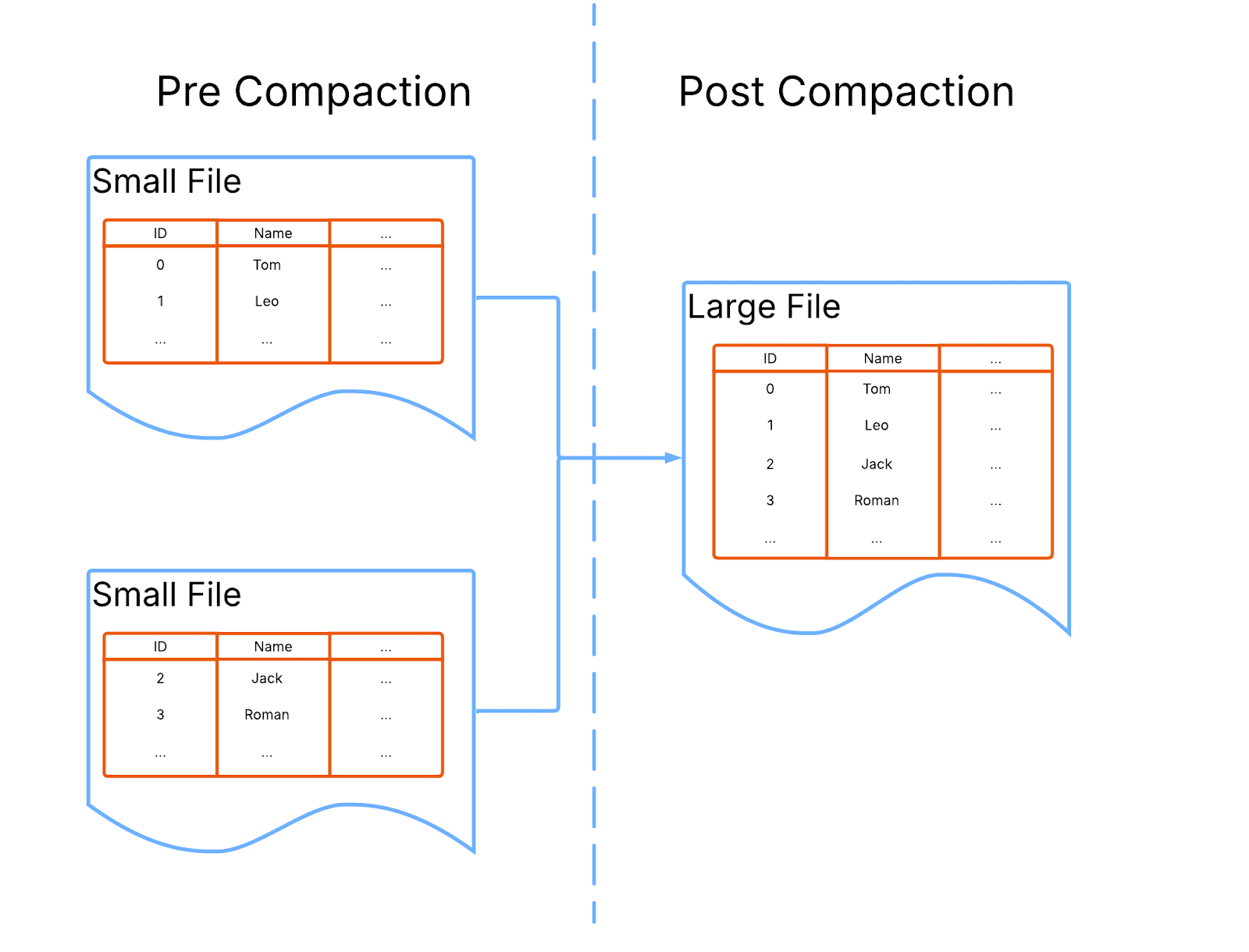
Snapshotting is not the only feature that suffers damage in the presence of small inserts in Iceberg. Such write patterns can also create many small files that wreck your general Iceberg query performance.
Standard Iceberg behavior dictates that every completed insert statement creates at least one new file.
Returning to our previous scenario where 2 rows are inserted and then 30 seconds later a further 2, would create 2 new Parquet files to store their respective data in.
Technically we still live in the world of Big Data and a file containing 2 rows is very small. The last thing you want is a table made up of millions of tiny files that:
Reduce read performance - To scan the data in the table every file must be opened, read and closed. This can increase query times by a missive amount.
Increase storage requirements - Files typically contain extra metadata, repeating this many times across many small files results in bloated inefficient use of disk space.
Worsen compression
Increase costs via more separate access requests - If your filesystem incurs extra costs for open/close operations (such as Amazon S3) then more files means more of these costs.
Complicate parallelization - Small files mean processing engines must make intelligent decisions around the way in which they combine files for parallelism. It is harder to define the optimum use of resources with this restriction.
The solution is to accumulate data before writing to Iceberg in bugger chunks but this can incur significant delay. To put this in perspective, the Parquet project (Iceberg’s most popular file format), recommends file sizes between 128Mb and 1Gb. Kafka messages are typically around 1Kb - 10Kb. Imagine a Kafka topic with 20 partitions receiving 5Mb/s. This would map to 250Kb/s per file (1 file per partition) and take 66 minutes to fill a 1Gb Parquet file. Not very real time, is it?
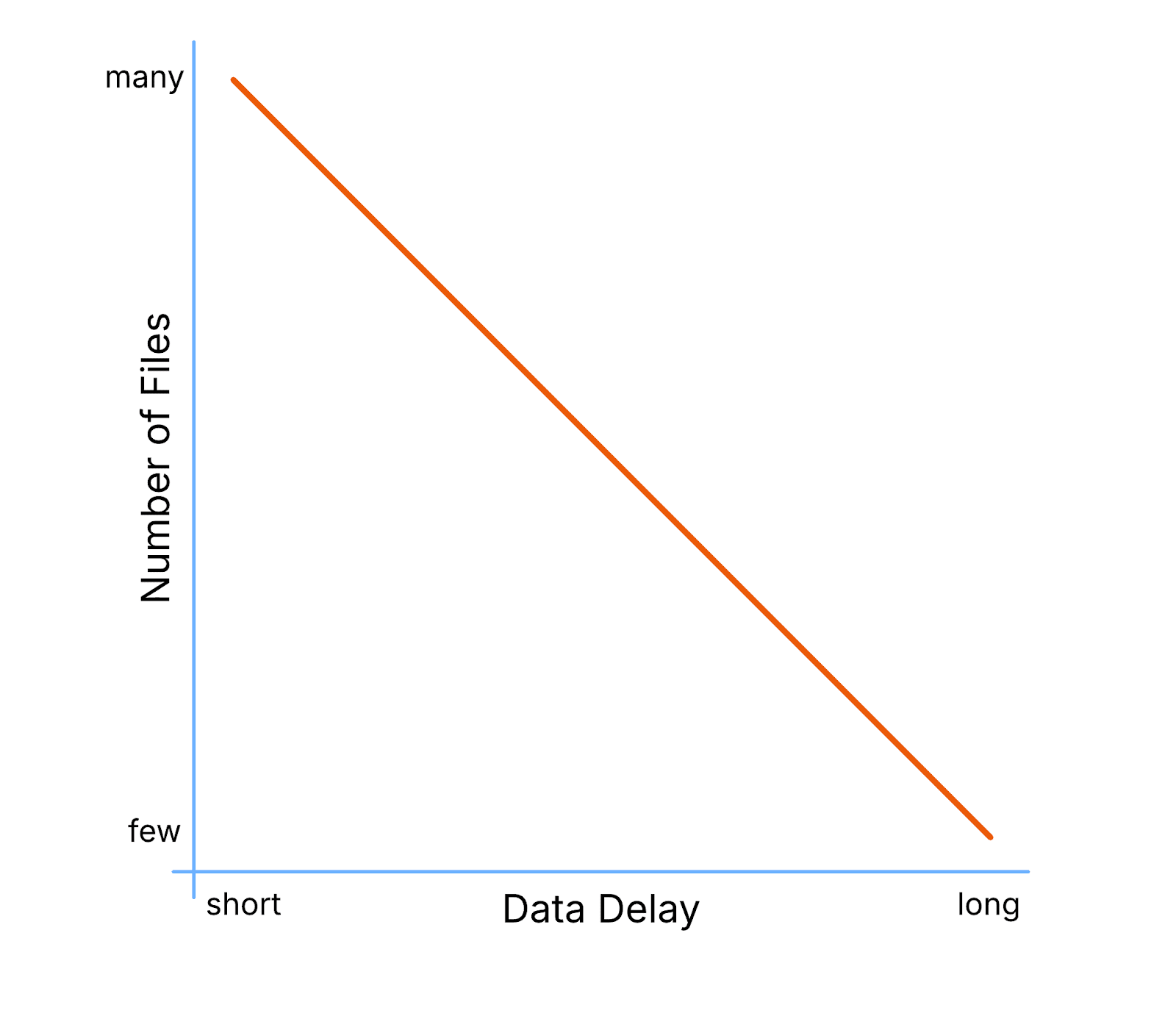
To counter this, streaming pipelines typically write inefficient small files into Iceberg first and combine them into larger files later. A process called Compaction. This is an essential housekeeping process and is manually triggered and monitored by your Iceberg administrator who must determine and orchestrate the data accumulation required to achieve freshness/efficiency balance required.
But again! Remember that Iceberg is only a format so cannot do the work by itself. 💡
Like snapshot expiration, It must rely on an external engine to perform compaction and this is not an automated background process.
Compaction determines the balance between freshness, performance, and cost and must be constantly maintained. Administrators should be constantly determining what the optimal file size should be and scheduling compaction when resources, a non trivial overhead.
Partition evolution
Partitioning is the fastest way to increase your Iceberg query performance by 100x or more.
It involves the organisation of data into subsets based on one or more column values. Query engines can take advantage of this organisation to only read the subsets relevant to the queries being executed.
For instance, given a table that is partitioned by timestamp and the query:
SELECT * FROM table WHERE timestamp = '2025-07-01';The query engine can “prune” away any other timestamps, greatly reducing the amount of data read to complete the query (and making it go a lot faster!).
As you can tell above, partitioning needs to be matched to the query to work effectively. If this is not the case it can actually reduce performance and cause serious problems including:
Reduced parallelism - Processing engines can parallelize by partition, reducing partitioning can reduce the maximum parallelization possible.
Under-utilization of system resources
Poor join performance - Joins can often be optimized by working with partitions rather than the full table. With poor partitioning this is not possible.
But what happens when you query patterns change? To maintain performance, partitioning must change along with them.
Iceberg supports “Partition Evolution” for this. Using a simple set of commands you can change the partitioned columns of your table to better match your query profiles.
Like most Iceberg maintenance operations this is a metadata only operation and so does not require the underlying data to be rewritten… yet.
Partition evolution applies only on data written after the partition spec has changed. Any earlier data still has the earlier spec applied and, whilst still available to queries, will not benefit from the increased performance promised by evolution.
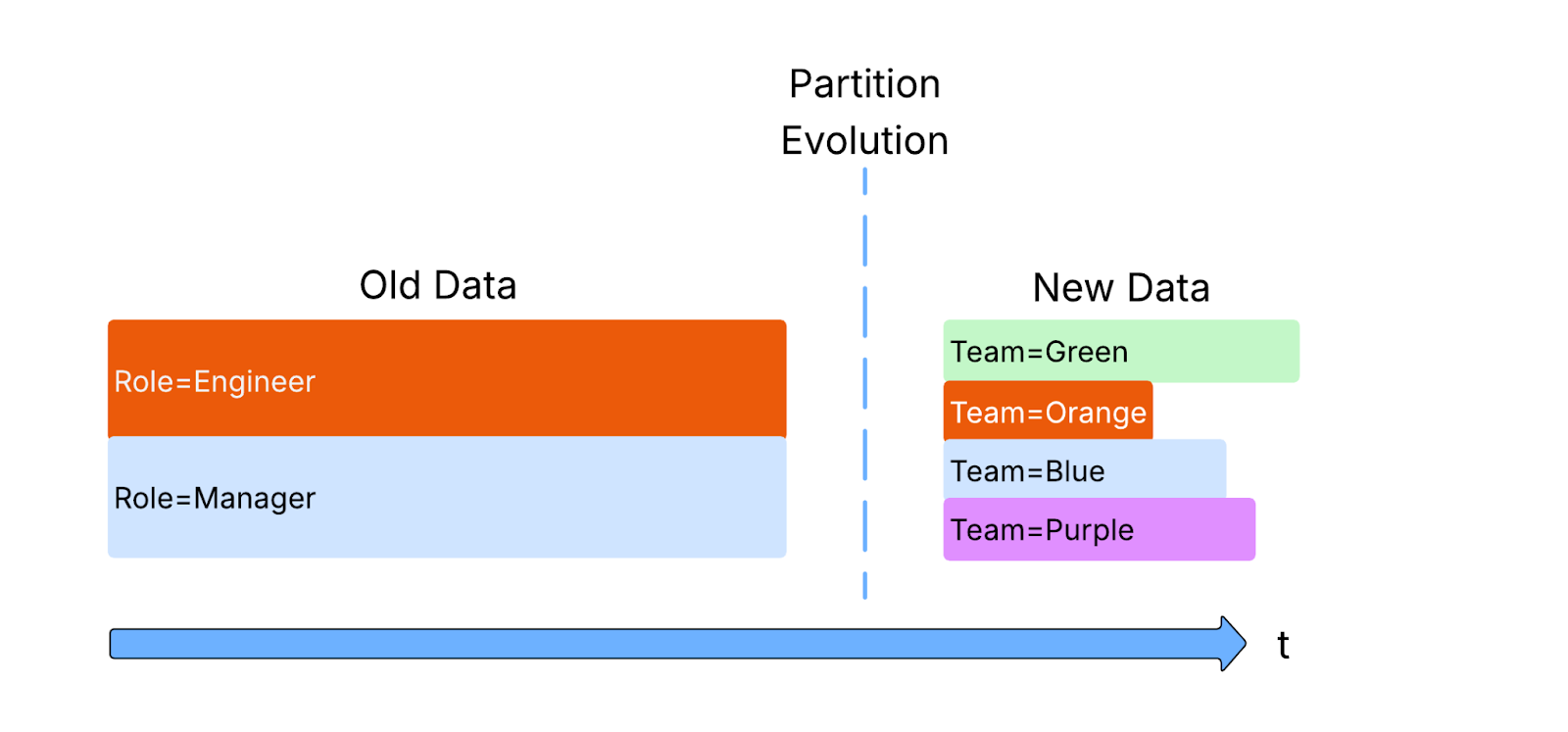
The solution to this problem is to rewrite old data to match the latest spec.
Once more however, remember that Iceberg is only a format so cannot do the work by itself. 💡
It must rely on an external engine to perform the required data rewrite. But this is a resource intensive process that can take a long time (think hours) to perform.
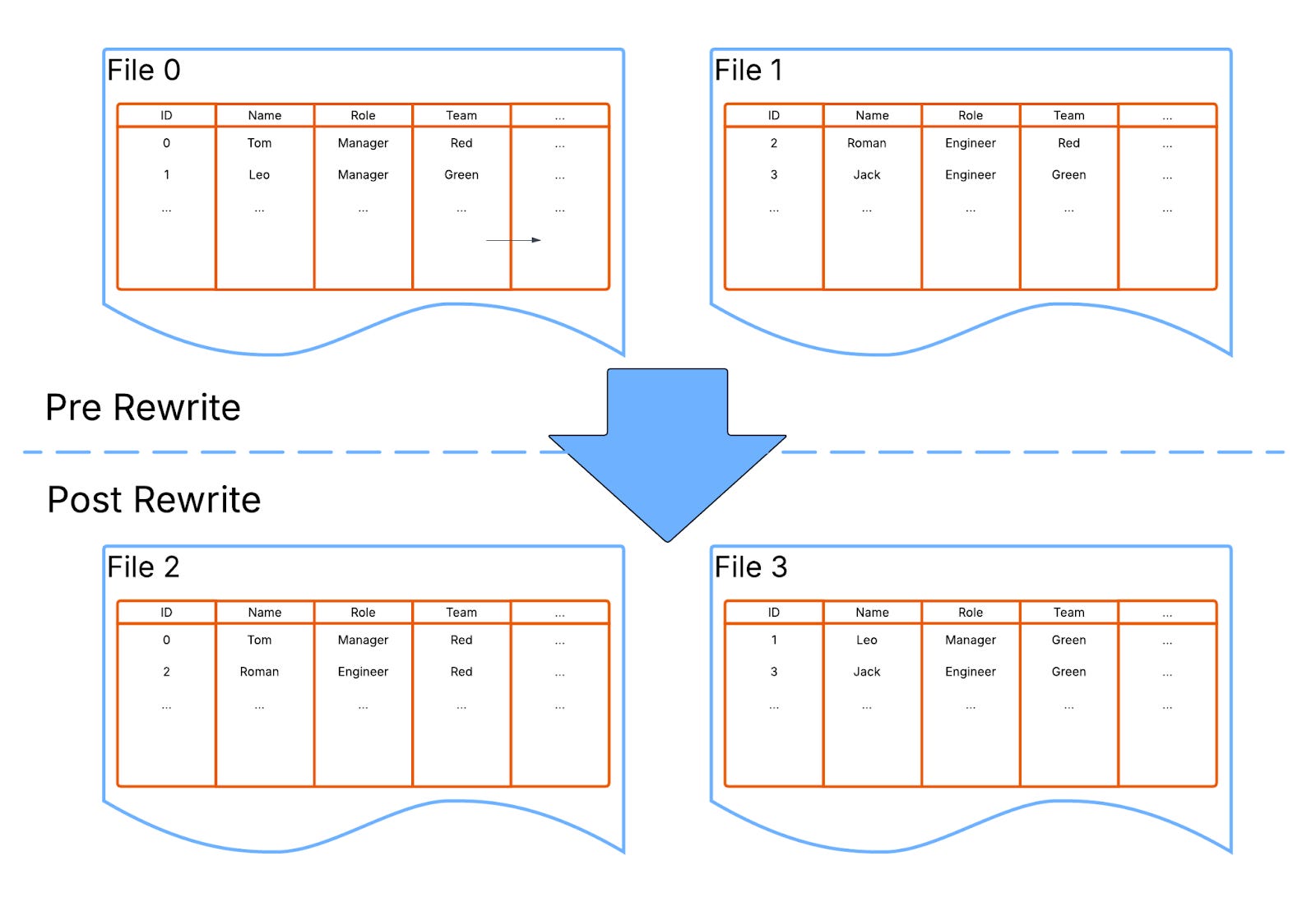
Iceberg administrators must pay attention to partitioning. At first this appears simple but, as volumes increase and query patterns change it can become complex, resource intensive and unpredictable.
Streambased to the Rescue
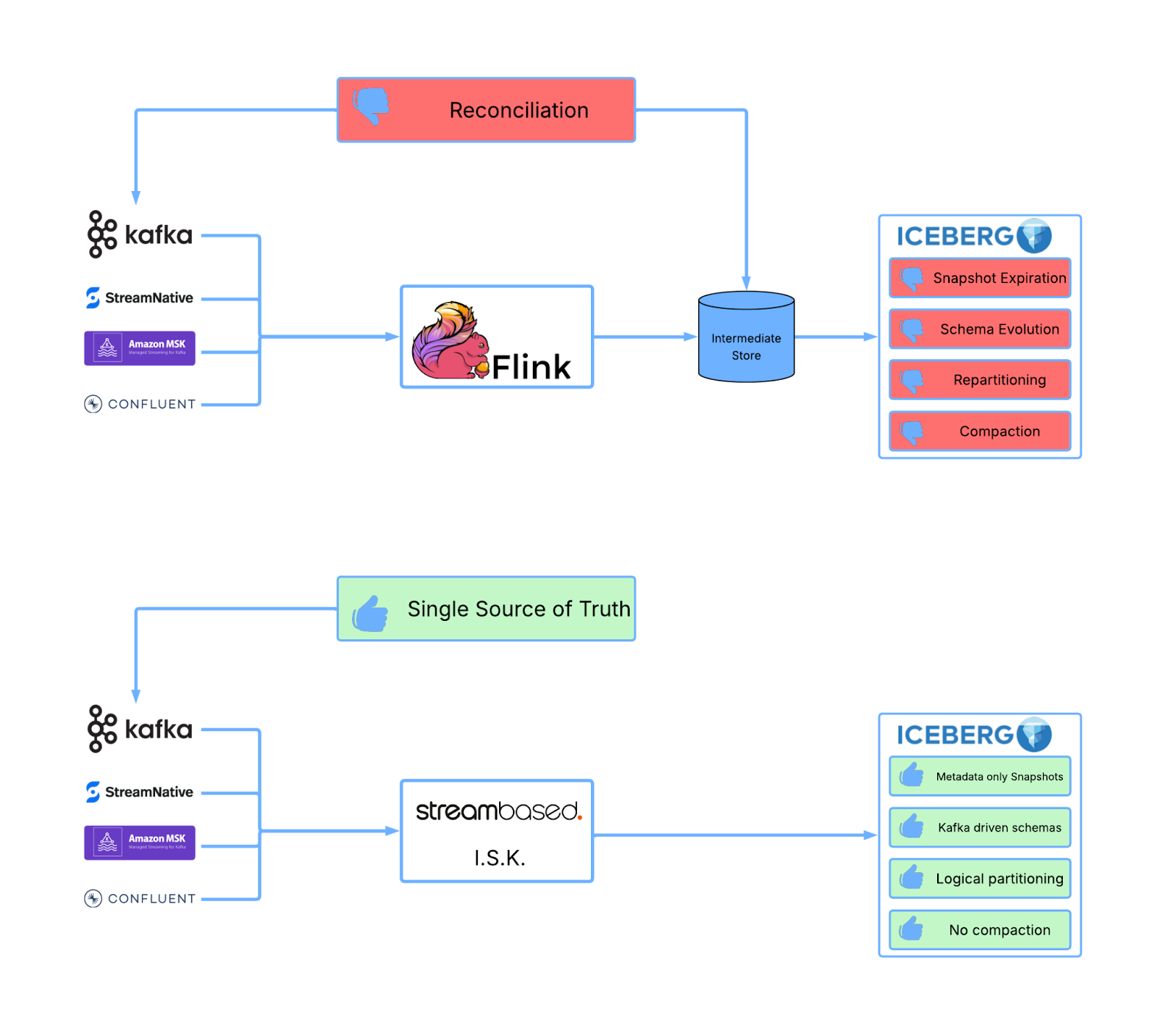
Up until now we’ve laid out a small selection of the administrative issues that plague Iceberg tables. It’s these issues that prompted us at Streambased to create I.S.K. (Iceberg Service for Kafka), an altogether simpler approach to streaming data via Iceberg.
Streambased performs an end run around all of this by surfacing Iceberg data as a logical projection rather than doing any physical movement of data.
In the Streambased approach the data that backs your Iceberg table remains in Kafka and ephemeral metadata is created on top of it. To clients, it appears as a normal Iceberg table but, when queries are executed, the data is read from Kafka, mapped and presented in a format clients are expecting
No data movement ahead of query time means no small files, no snapshots and no uncomfortable partitioning decisions. Instead, slice your data the way you want to at the point at which it is read. The need for Compaction is completely negated as the source system (Kafka) is responsible for the data layout, not Iceberg.
To maintain performance, Streambased indexes the data in Kafka as it is written or read for operational purposes. These indexes allow Streambased to mimic Iceberg features such as:
Partitioning: Using indexes, Streambased can target sections of Kafka data that are relevant to particular queries creating a similar outcome to Iceberg’s tradition partitioning. The advantage of taking this approach is that indexing is not tied to the physical layout of files on disk and so require no rewrite and no delays.
Snapshots: Snapshots in Streambased are also related to indexing. Kafka data is already indexed by timestamp and other insert markers so identifying the sections relevant to a particular time period is an easy task. This means Streambased can impose any number of snapshots on the data as required by the clients and that these imposed snapshots can not and need not ever be expired..
Streambased repositions the source system (Kafka) as the source of truth for both operational and analytical applications, removing the need for intermediate data stores and the expensive maintenance operations that come along with them.
Conclusion
Ultimately, as organizations continue to embrace streaming architectures and real-time analytics in their lakehouse, the operational complexities of managing Iceberg in its traditional form become increasingly apparent.
Streambased offers a refreshing rethink, one that aligns better with the dynamism of modern data flows by abstracting away the burdens of compaction, snapshot expiration, and partition evolution.
With Streambased, not only is your Kafka data instantly accessible by any engine that supports iceberg, but you also don’t have to deal with any of the complexities of managing it.
Can this work if my Kafka server data is expired every 2 hours?
Great post! Sounds like ISK is almost a DB engine with iceberg as the file format.