From Pipelines to Composable Data: Rethinking CDC
Stop writing every change: combining logs and tables for a simpler, real-time CDC model


Change Data Capture (CDC) has become one of the foundational patterns of modern data systems. At a high level, it’s a simple idea: instead of periodically copying entire datasets, we track changes as they happen. Databases emit inserts, updates, and deletes as a continuous stream of events, and downstream systems replay those events to reconstruct the latest state. In practice, this pattern fits naturally with streaming systems like Kafka, which act as an ordered log of changes, enabling real-time processing and distribution.
As architectures have evolved toward lakehouses, however, CDC’s reach has expanded. Apache Iceberg, for example, plays a very different role from the database copies that were the initial remit of CDC but the concept of a continuously updated data lake is too attractive to pass up. To emphasize the point, Iceberg is currently doing to disparate and fragile ETL interfaces what Kafka did to operational interfaces a decade ago. Having CDC data in Iceberg makes it available to an entire organisation, not just an isolated database endpoint.
Iceberg is designed as an analytical storage layer, however, optimized for large-scale reads over immutable files in object storage. The traditional pipeline capturing CDC from a database, streaming it through Kafka, and materialising it into Iceberg quickly encounters issues that expose limitations in Iceberg’s design for fast data.
The root of the problem lies in a mismatch of granularity. CDC operates at the level of individual rows, capturing each change as a discrete event. Iceberg, by contrast, operates at the level of files. Once a file is written, it is effectively immutable. This means that even the smallest update cannot be applied in place. Instead, the system must locate the file containing the affected row, mark the original version as deleted, write a new version of the row into a new file, and then commit an updated snapshot of the table. What appears to be a trivial change at the logical level becomes a surprisingly heavy operation at the storage layer.
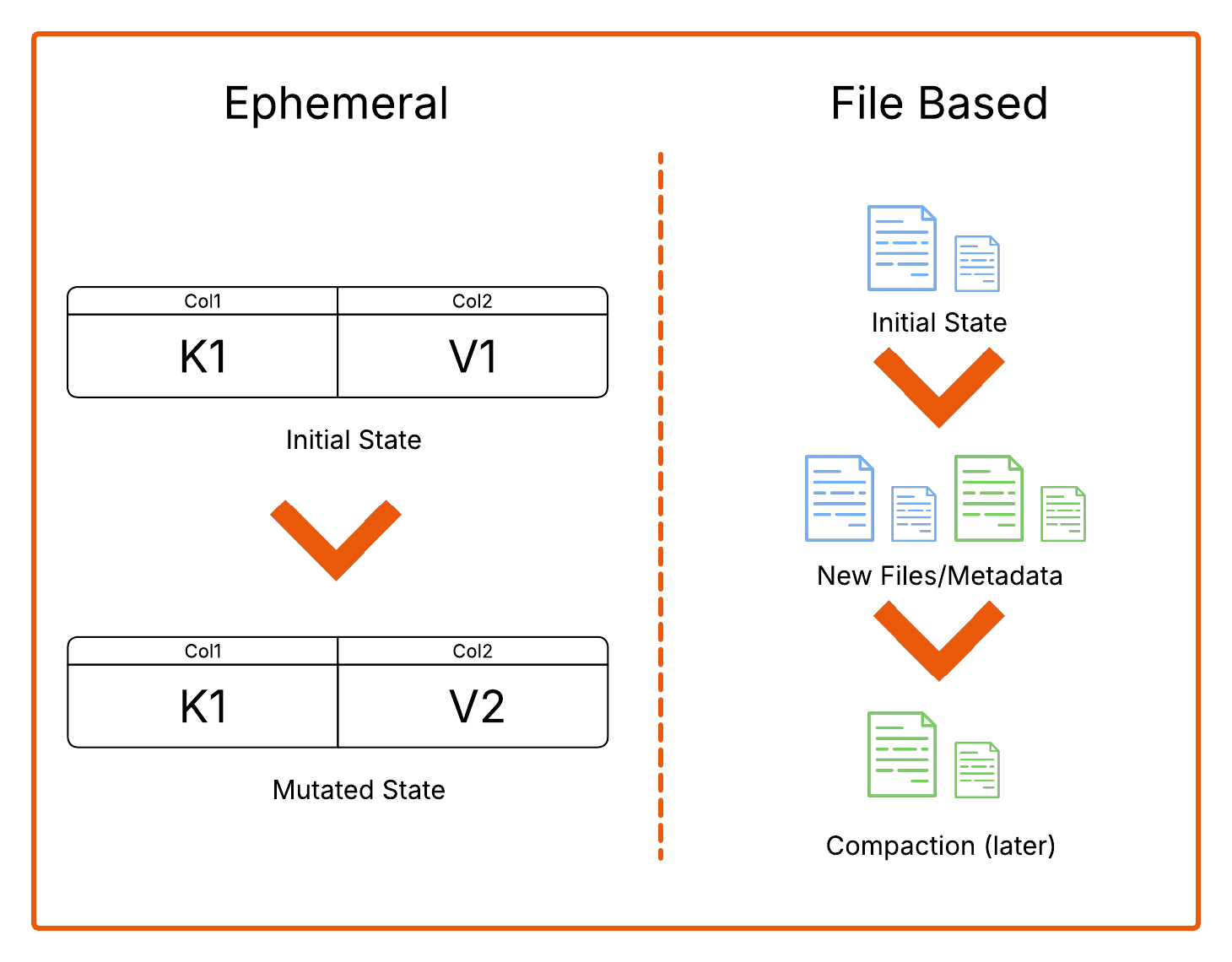
Over time, this mismatch creates compounding issues. Small updates trigger disproportionately large amounts of work, leading to a proliferation of small files and metadata. Deletes and updates are not spared, these accumulate as separate delete files, which increase the cost of query planning. None of these problems are insurmountable, Iceberg has compaction and deduplication processes able to restore efficient data and metadata layouts but these are heavyweight and their execution must also be carefully managed. In short, the operational overhead is large enough to consider whether the result is really worth it in the end?
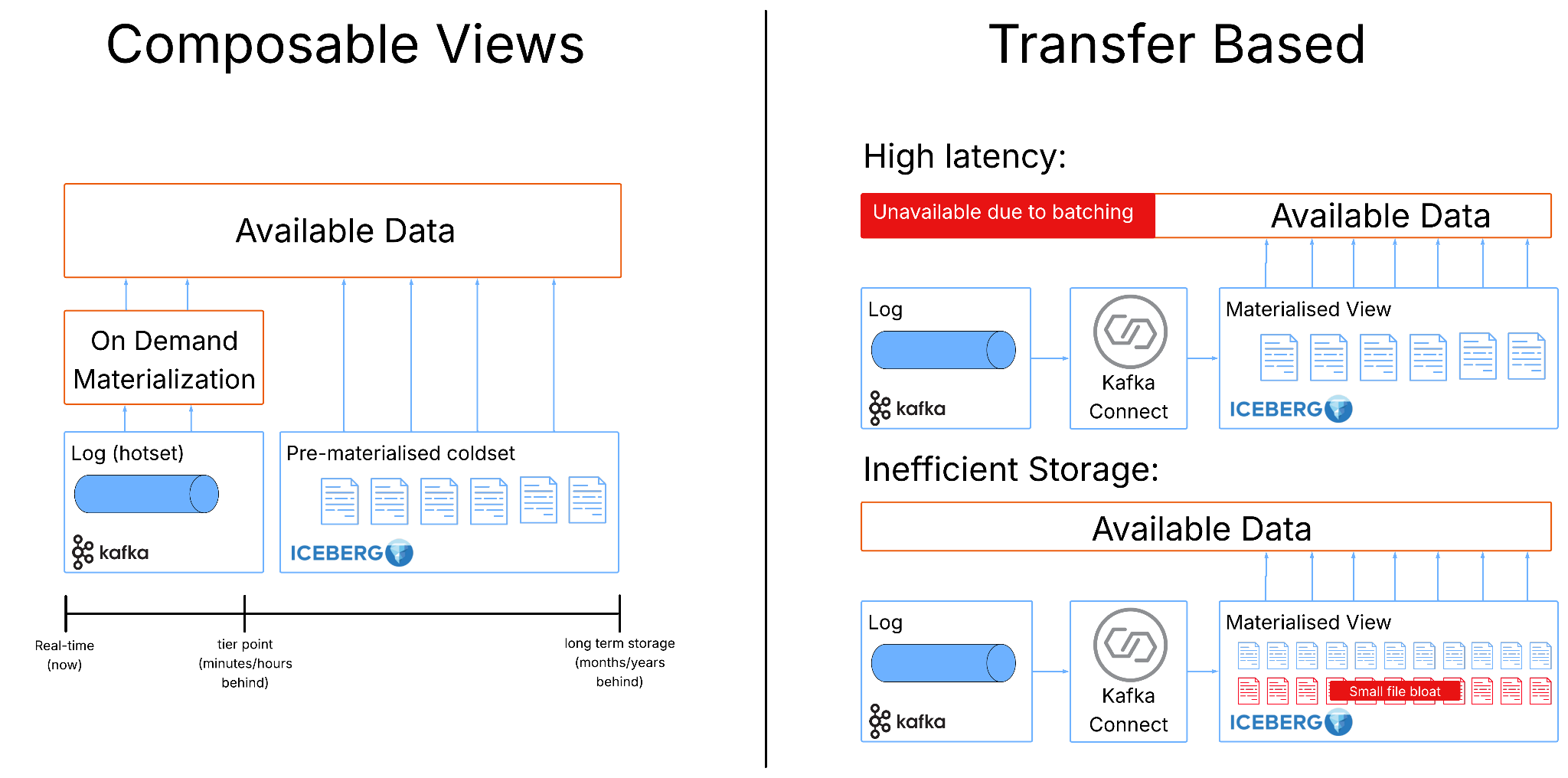
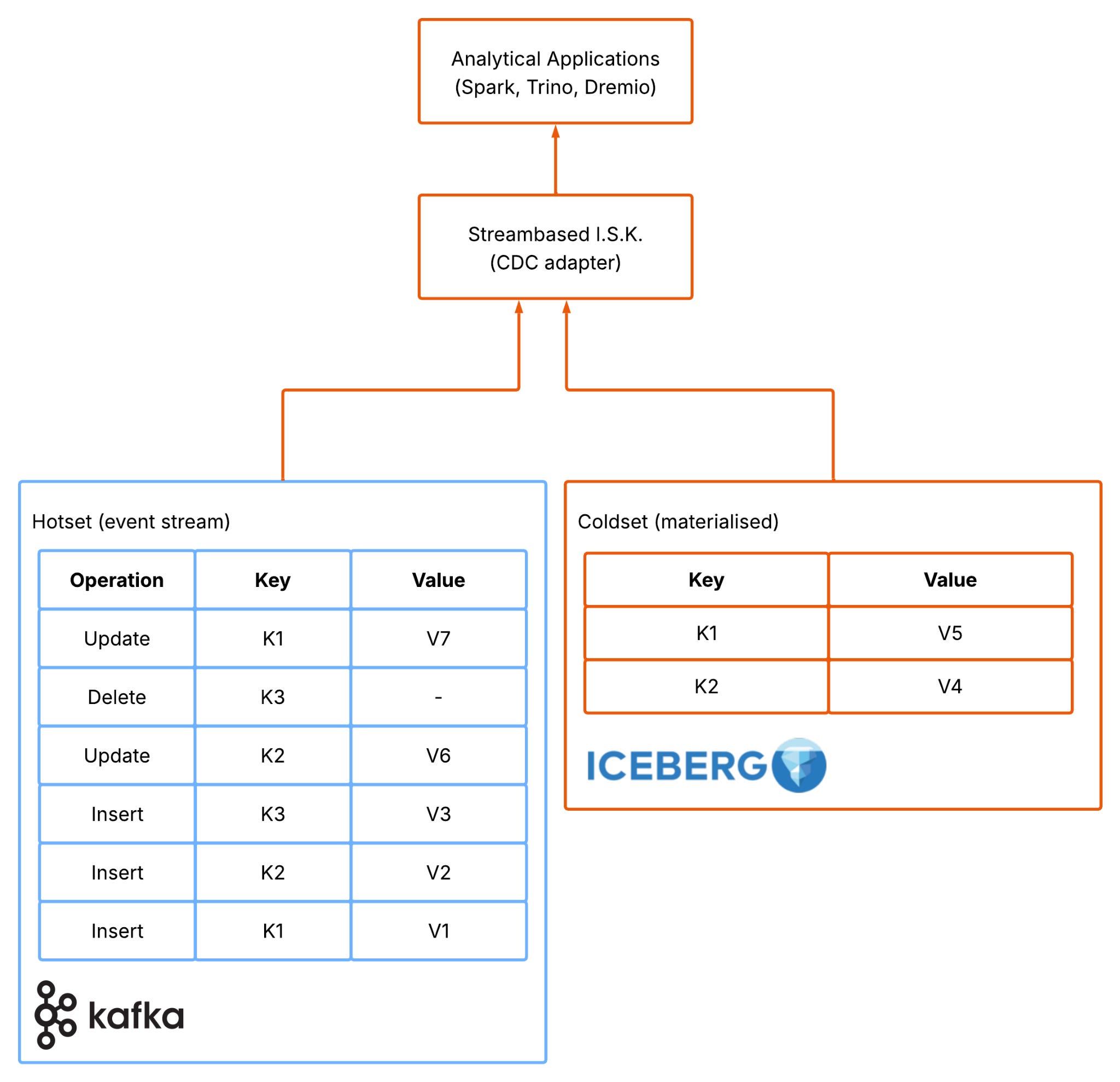
Streambased’s approach starts by embracing a distinction between log based event stream and materialised tables instead of fighting it. Rather than insisting that all data must be materialised into Iceberg before it can be queried, the dataset is split into two complementary parts. One part (the “coldset”) is fully materialised and lives in Iceberg, representing the stable, finalised, historical view of the data. The other part (the “hotset”) remains in Kafka as an ephemeral stream of recent changes. Queries operate across both, combining the durable cold data with the live hot data to produce a complete and up-to-date view. The sections are composable with the size of the two sections balanced according to the workload they serve. An easy to explain (but very naive) composition may expand the hotset (say last 6 hrs) for workloads that expect many updates and deletes to avoid accruing metadata in Iceberg but may have a much smaller hotset (say last 15 mins) for workloads that are primarily insert of new rows (a much less expensive operation in well partitioned Iceberg).
This shift has a subtle but powerful effect. By allowing recent data to remain in Kafka, the system avoids the constant pressure to translate every small change into file-level operations. In this sense, materialisation becomes a controlled, deliberate step rather than a continuous background process. Operators are free to make informed decisions about how and when materialisation happens and can accept the right tradeoffs for their use cases.
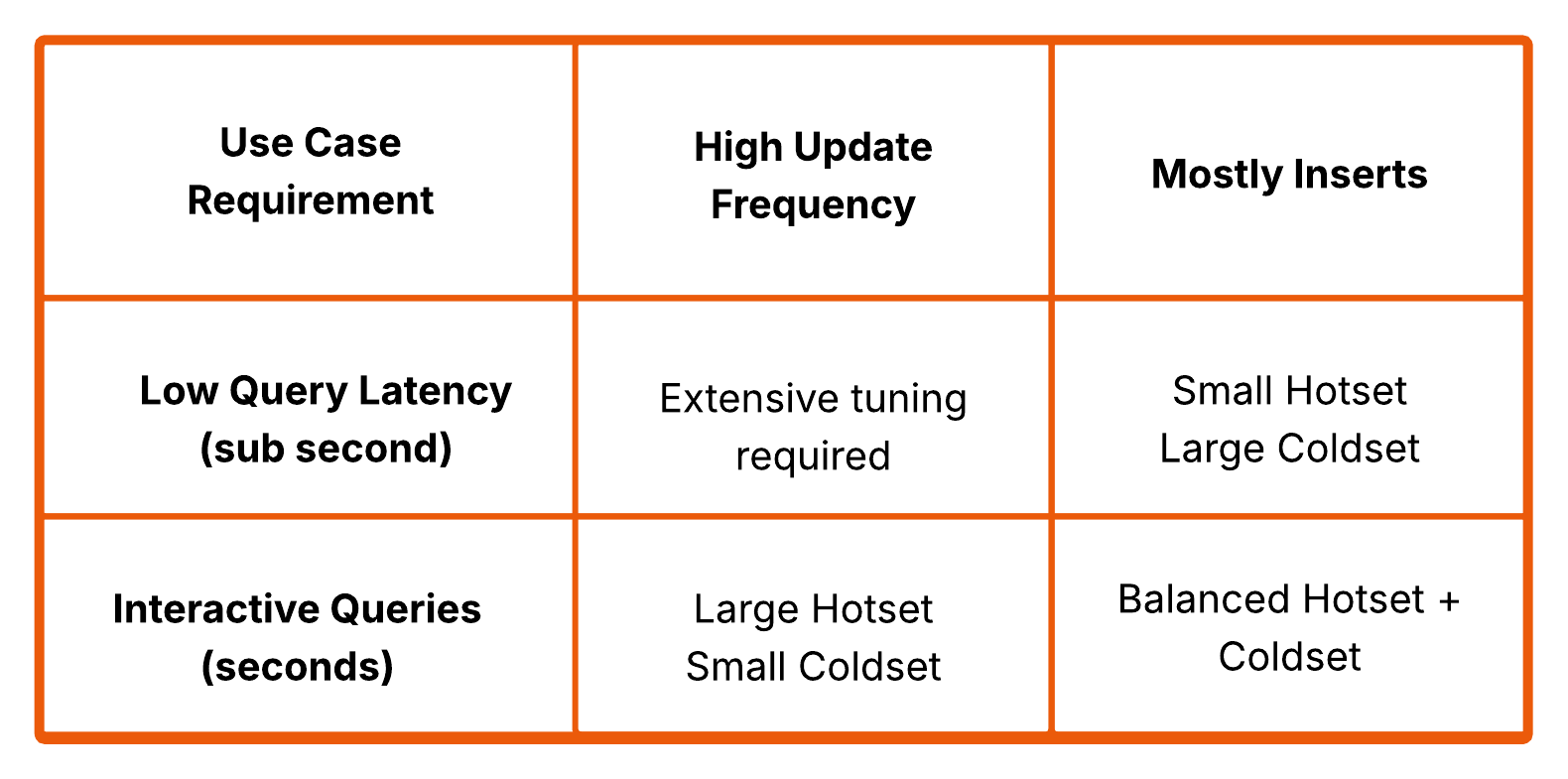
This model also aligns closely with how data behaves in real systems. Most datasets exhibit a clear distinction between recent, high-churn data and older, relatively static data. The last few hours or days tend to be latency-sensitive and subject to frequent updates, while older data is rarely modified and is primarily accessed for analysis. Kafka is well suited to handling the former, providing low-latency access to recent events, while Iceberg excels at storing the latter efficiently and cheaply over long periods.
By splitting the dataset along this natural boundary, the system can take advantage of both technologies without forcing either to operate outside its strengths. Kafka retains its role as the system of record for recent changes, enabling real-time querying and processing, while Iceberg provides a scalable, cost-effective store for long-term data. Importantly, this also reduces the need for heavy operational machinery. Many of the maintenance steps that plague traditional CDC pipelines: compaction, snapshot cleanup, repartitioning, become either less frequent or unnecessary, because the system avoids generating excessive intermediate state in the first place.
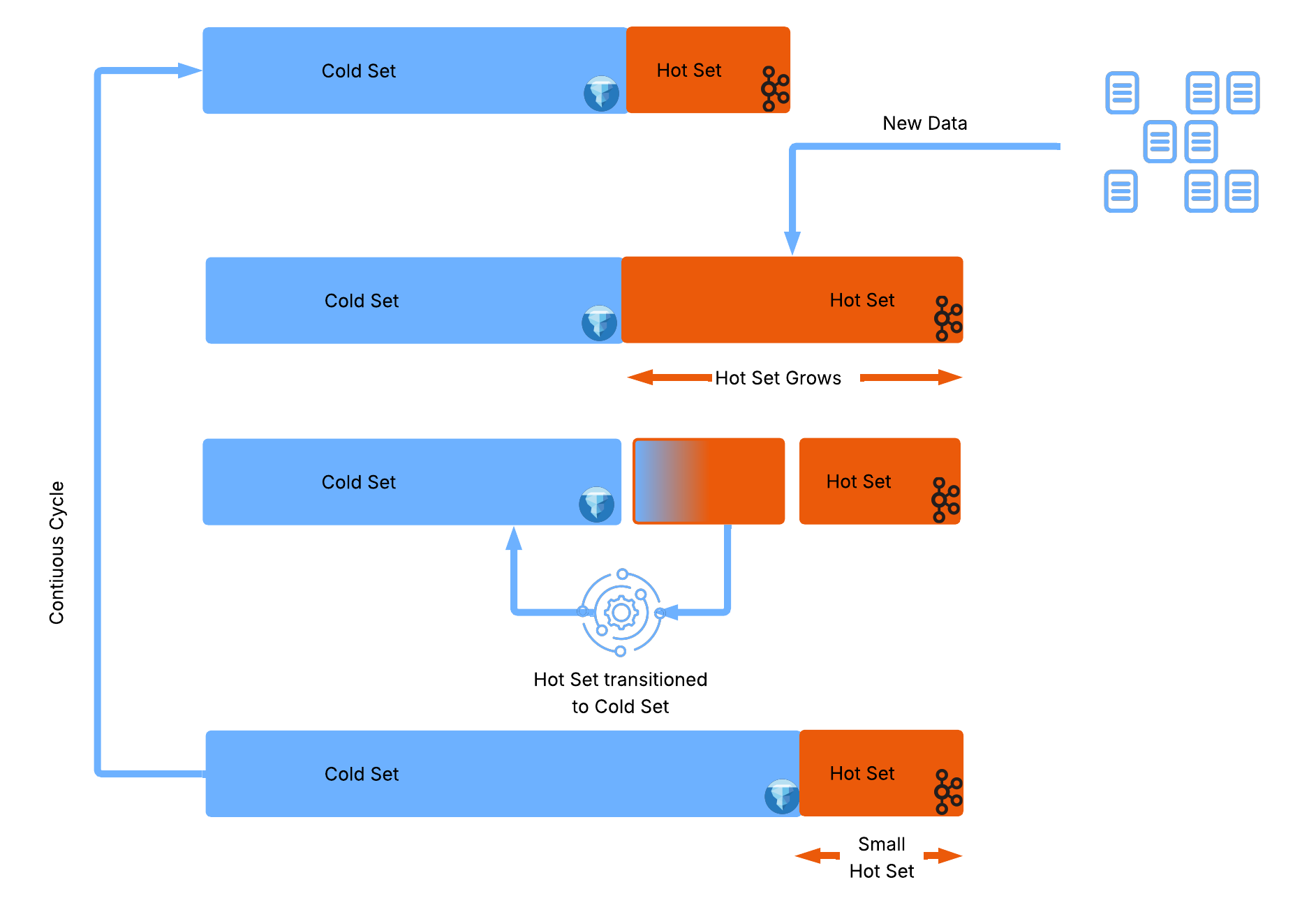
Another consequence of this approach is that it restores the immediacy that CDC promises. In a fully materialised pipeline, there is always a delay between when an event occurs and when it becomes visible in Iceberg. Queries are effectively bounded by the last successful write. In contrast, when queries incorporate the live Kafka stream, newly arrived events are immediately reflected in results. The system is no longer querying a slightly outdated snapshot but is instead computing state directly from the most recent data available. The cost of this “zero latency” is a small amount of extra work at query time, where the system reconciles the Iceberg snapshot with the latest events in Kafka. Instead of reading a fully precomputed table, the query “plays forward” the recent portion of the log to produce the current state.
In practice, this is a favourable trade. The additional compute is limited to the hot data window, while the system avoids the much larger ongoing costs of constant writes, compaction, and maintenance in Iceberg. Rather than paying continuously for freshness, you pay only when you query, and only over a small slice of data.
Ultimately, this leads to a different way of thinking about CDC in the lakehouse. Instead of viewing it as a process of continuously writing changes into tables, it becomes a matter of composing views over a combination of log and storage. Kafka holds the evolving, mutable edge of the dataset, while Iceberg holds the stable, immutable core. The full state emerges from the interaction between the two, rather than being fully materialised in either system at all times.
The real issue isn’t that CDC is hard in Iceberg, it’s that we’re solving the wrong problem.
Fully materialising every change is an assumption carried over from older architectures. In a log-first world, it’s unnecessary. The log already contains the truth; Iceberg only needs to store the parts of that truth that have stabilised.
Once you accept that, the solution becomes obvious: stop writing everything, all the time. Let Kafka handle change, let Iceberg handle history, and draw from both as required and only when you need to.